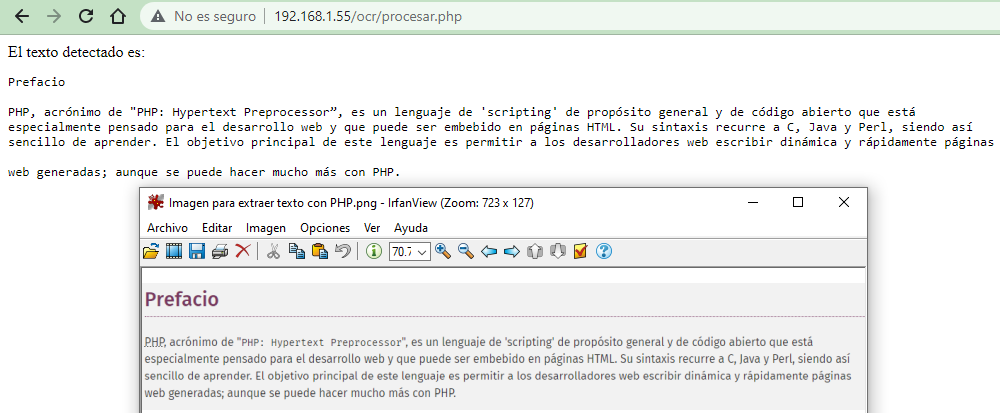
Extraer texto de imagen con PHP y Tesseract – OCR
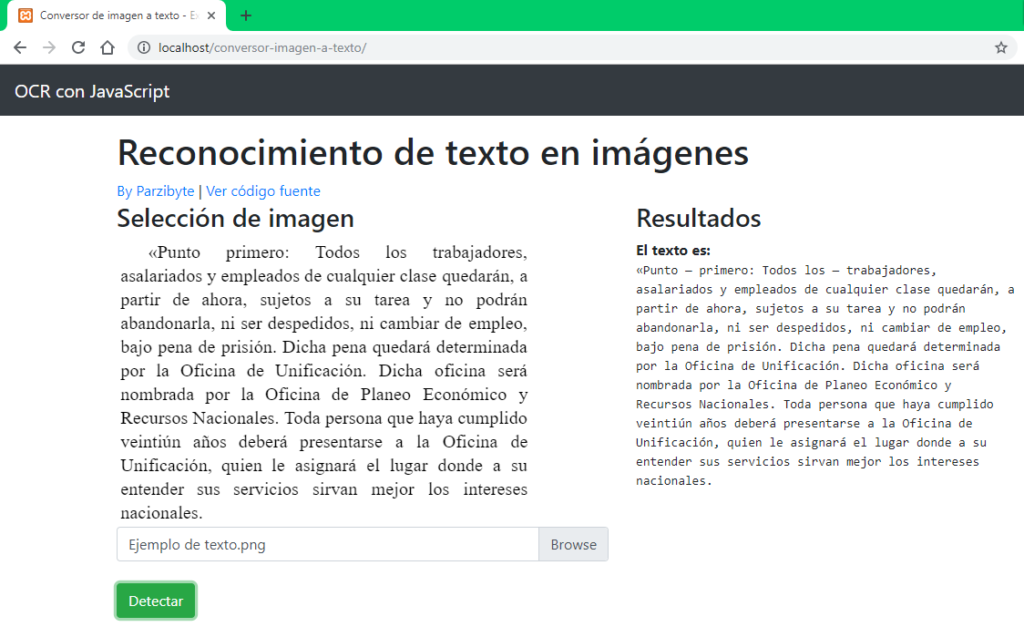
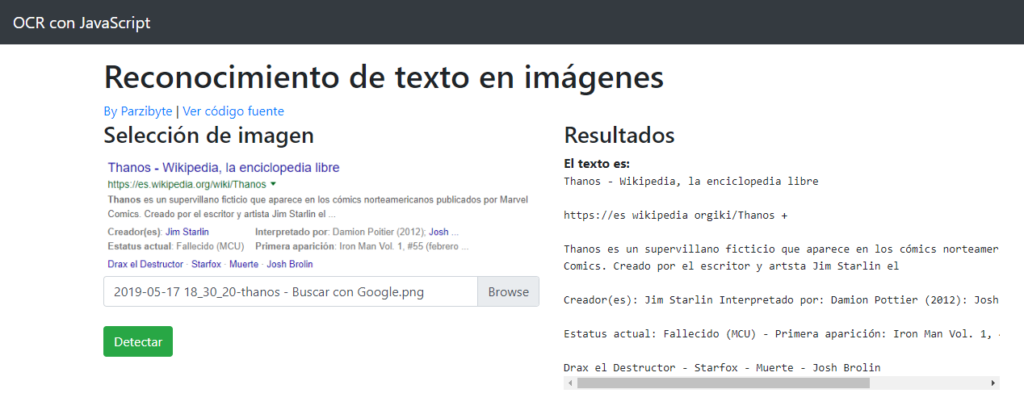
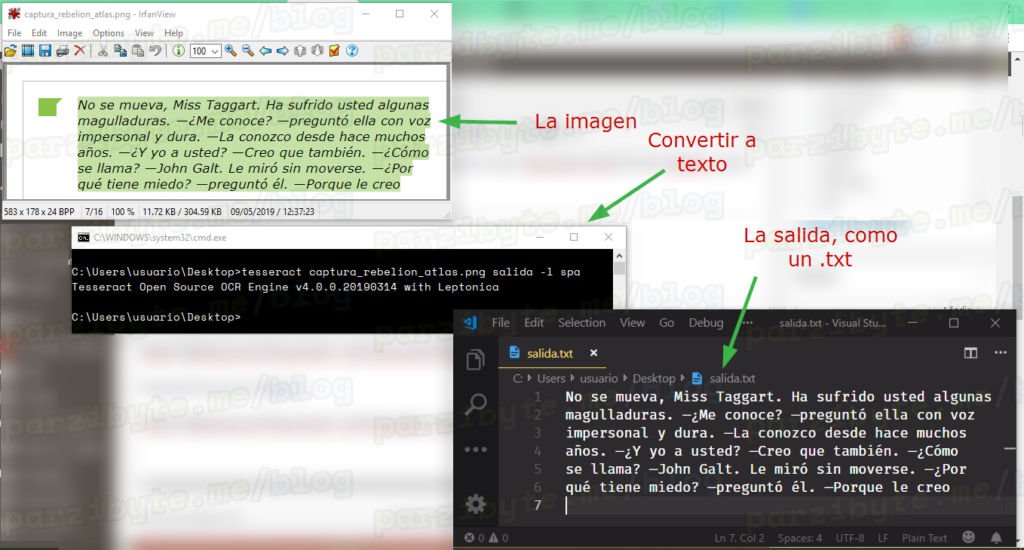
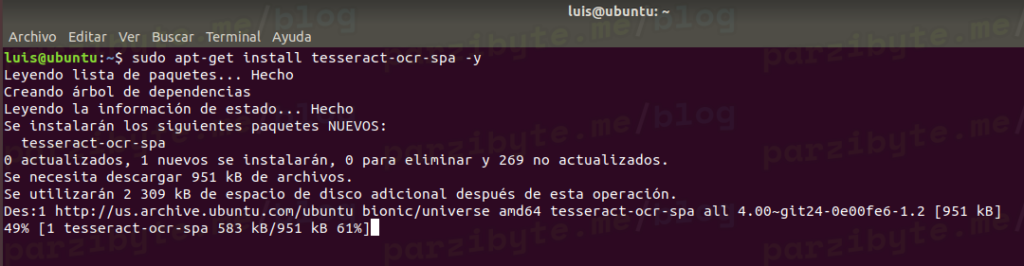
En este post de programación en PHP te mostraré cómo extraer el texto de imágenes o mejor dicho cómo usar Tesseract OCR desde este lenguaje, de modo que podamos digitalizar el texto de una imagen usando PHP. Al final esto que te muestro es un simple wrapper o una envoltura, ya que si bien vamos […]
Extraer texto de imagen con PHP y Tesseract – OCR Leer más »