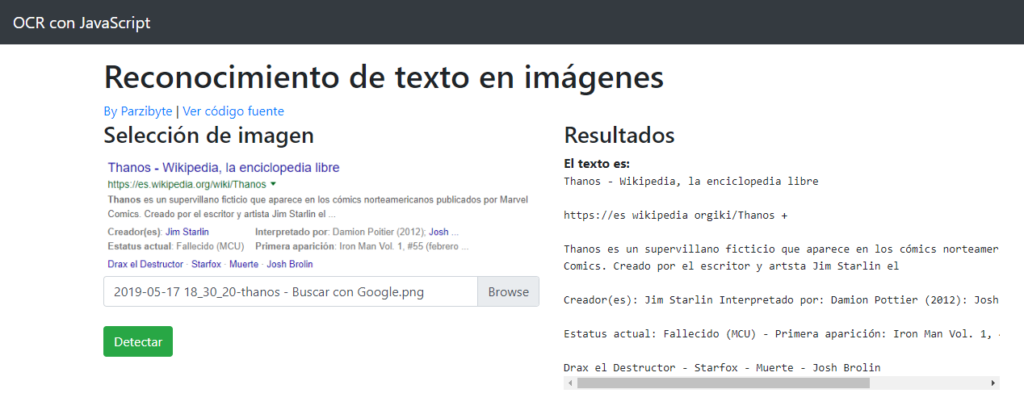
Ya estamos en otro post sobre el reconocimiento óptico de caracteres, que no es otra cosa más que detectar el texto que existe dentro de una imagen, es decir, extraer el texto de una imagen.
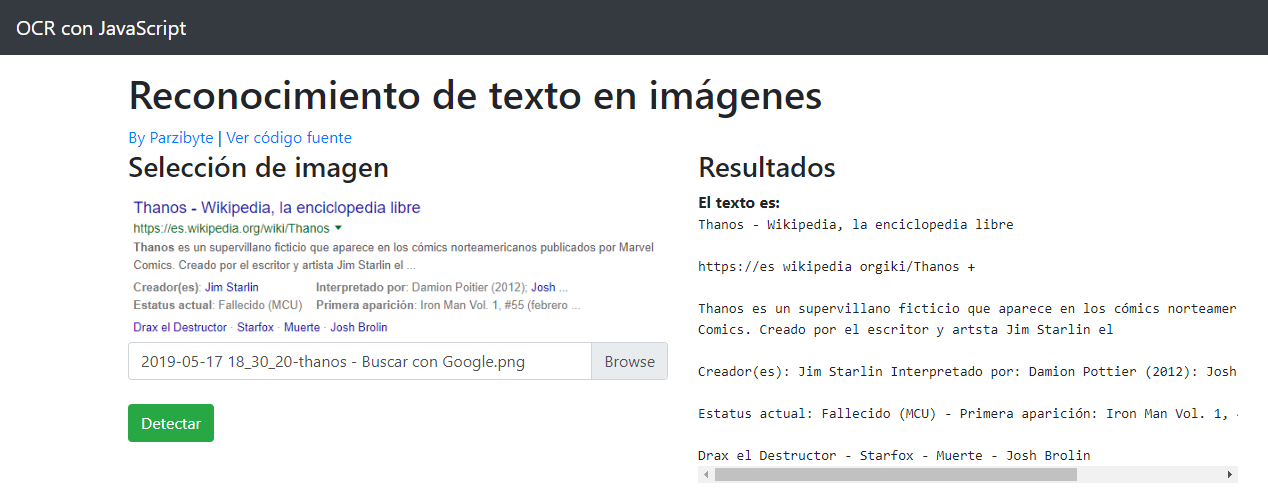
Lo hicimos con Tesseract OCR en Windows y Linux, pero ahora lo haremos en un lenguaje de programación que se ejecuta en el navegador: JavaScript.
Sí, estás leyendo bien, vamos a extraer el texto de una imagen con JavaScript, usando Tesseract OCR, el cual es un motor de reconocimiento óptico de caracteres.
Tesseract.js
La librería Tesseract JS extrae palabras de casi cualquier idioma a partir de imágenes, es decir, extrae el texto de una imagen.
tesseract.js puede ejecutarse directamente en el navegador, ya que es propiamente un archivo de JavaScript.
Internamente es un ajuste del motor Tesseract OCR traído a JavaScript gracias a emscripten.
Por cierto, tesseract.js utiliza Web Workers.
¿Quieres usar esto de manera nativa en Windows o Linux, o quieres ver una demostración? click aquí.
Uso de tesseract.js en el navegador
Podemos importar la librería con un script, o descargar el archivo, pues al final es un fichero con extension .js.
Gracias a unpkg podemos importar el script de un rápido CDN, en mi caso es:
https://unpkg.com/tesseract.js@2.0.0-alpha.7/dist/tesseract.min.js
Estoy usando el último release publicado en GitHub, si cuando consultas este post eso cambia, simplemente actualiza lo que va después del arroba.
Tesseract y TesseractWorker
Al importar el script podremos invocar a un WebWorker de Tesseract creando un nuevo objeto de tipo Tesseract.TesseractWorker y llamando al método recognize dentro del mismo, el cual regresa un TesseractJob (algo parecido a una promesa) y acepta los siguientes argumentos:
- La imagen de la cual vamos a extraer el texto
- El idioma o idiomas. Para el español es spa, y si quisiéramos el español como el inglés entonces sería spa+eng, es decir, separándolos con el signo de más (
+). - Un objeto de opciones de
Tesseract
Ese TesseractJob tendrá sus métodos then, catch, finally y uno muy interesante: el progress.
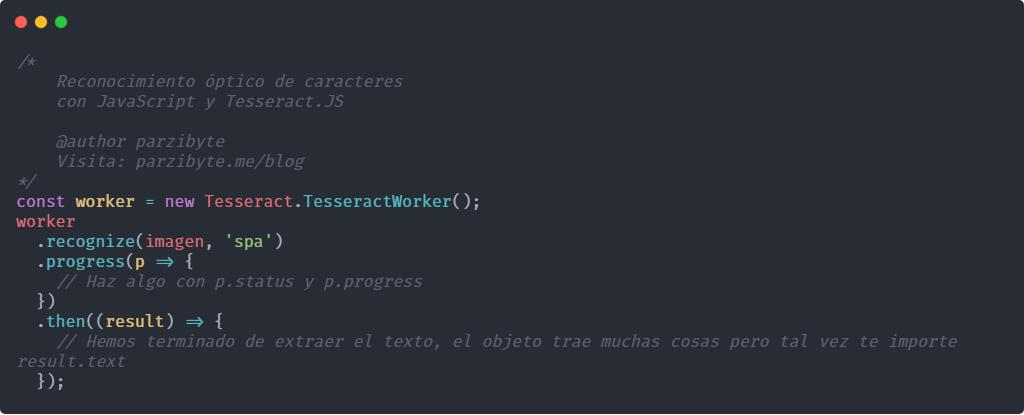
Veamos un ejemplo:
const worker = new Tesseract.TesseractWorker();
worker
.recognize(imagen, 'spa')
.progress(p => {
// Haz algo con p.status y p.progress
})
.then((result) => {
// Hemos terminado de extraer el texto, el objeto trae muchas cosas pero tal vez te importe result.text
});La imagen
La imagen puede venir de:
- Un elemento HTML de tipo
img,canvasovideo - Un objeto de tipo
File, obtenido de uninputfile - Una ruta de una imagen accesible desde el navegador
Así que podemos indicar simplemente la URL de una imagen o pasarle la imagen obtenida de un input
Pistas para obtener la imagen
Como lo dije, podemos indicar la imagen como una ruta; u obtenerla de un input.
Definimos un input:
<input type="file" id="mi_input">
Obtenemos una referencia al elemento:
const $mi_input = document.querySelector("#mi_input");
Ahora los archivos estarán en $mi_input.files
Para reconocer la imagen (en el click de un botón o en el change del input) le pasamos al worker lo que haya en $mi_input.files[0], es decir, el primer archivo del input.
El progreso
El worker invocará a progress en cada avance que haga, porque el proceso puede tardar dependiendo del poder de la computadora.
En cada invocación a progress el valor traerá dos datos útiles: status y progress
status: el estado, una leyenda de lo que está haciendo (por ejemplo, detectando el texto)progress: un valor flotante que indica el porcentaje
Podemos escuchar estos avances y mostrarlos en un párrafo o en barras de carga, todo queda en nuestra creatividad, tiempo y requisitos, en caso de que existan.
El resultado
Cuando la promesa se resuelva (en el then) traerá el resultado, el cual es un objeto que tiene los datos del texto extraído de la imagen, es lo que tanto esperamos, es en donde la magia sucede.
Dicho objeto tiene muchos datos, pero la propiedad en donde está el texto se llama text.
Conclusión
En conclusión debes importar el archivo, crear un worker de Tesseract.TesseractWorker, llamar al método recognize y manejar el progress, then, catch y finally,
Una cosa muy importante es manejar el catch, pues si hay errores los mismos serán reportados ahí.
Muy pronto traeré una aplicación de ejemplo para que veas el uso en vivo.

Hola, soy muy nuevo en esto y he seguido todos los pasos que has indicado con el Tesseract OCR para leer una imagen y extraer su texto, pero … me quedo clavado en ejecutar el código que pones al final, sobre el .js y el WORKER. ¿Podrías ayudarme?. Otra cosa, ¿Se puede extraer sólo el texto deseado?, es decir, al leer una imagen sólo quiero un texto en concreto, realizando modificaciones en el script que lee el documento?. Muchas gracias por todo y por tu aporte.
Hola. Para que el script solo lea determinada parte puedes cortar el texto obtenido, es decir, obtener los primeros N caracteres, o recortar la imagen para que solo se lea el mensaje que quieres.
Sobre tu otra duda; es muy general, ¿podrías ser más específico?
Un saludo
Hola una pregunta en caso de querer guardar la imagen en un servidor como lo puedo hacer … agradeceria tu ayuda
Hola, si quieres guardar la imagen simplemente usa un FormData y envíala al servidor en cuanto el usuario la seleccione.
Si usas PHP, mira esto: https://parzibyte.me/blog/2018/11/06/cargar-archivo-php-javascript-formdata/
Si por casualidad usas CodeIgniter y jQuery puedes ver esto: https://parzibyte.me/blog/2018/04/20/subir-foto-jquery-servidor-php-codeigniter/
Avísame por cualquier otra cosa. Saludos 🙂
Hola otra vez muchas gracias por tu respuesta … cualquier otra cosa me vuelvo a poner en contacto.
Claro, no te preocupes 🙂
Pingback: Extraer el texto de una imagen con JavaScript y Tesseract.js - Aplicación web - Parzibyte's blog