En este post vamos a ver cómo convertir imágenes a texto; es decir, leer el texto que está dentro de una imagen; ya sea una foto de un libro, una captura de pantalla o una imagen escaneada.
A esto se le llama digitalización de textos, reconocimiento óptico de caracteres u OCR. Vamos a usar Tesseract OCR, el cual es un proyecto open source que trata sobre un motor de reconocimiento de texto en imágenes.
Recuerda que ya vimos cómo se instala y configura en Windows 10 y en Ubuntu.
Vamos a probar el reconocimiento óptico de caracteres con muchas imágenes, es decir, leer el texto de una imagen ya sea desde una captura de pantalla o una foto, incluso desde un escaneo.
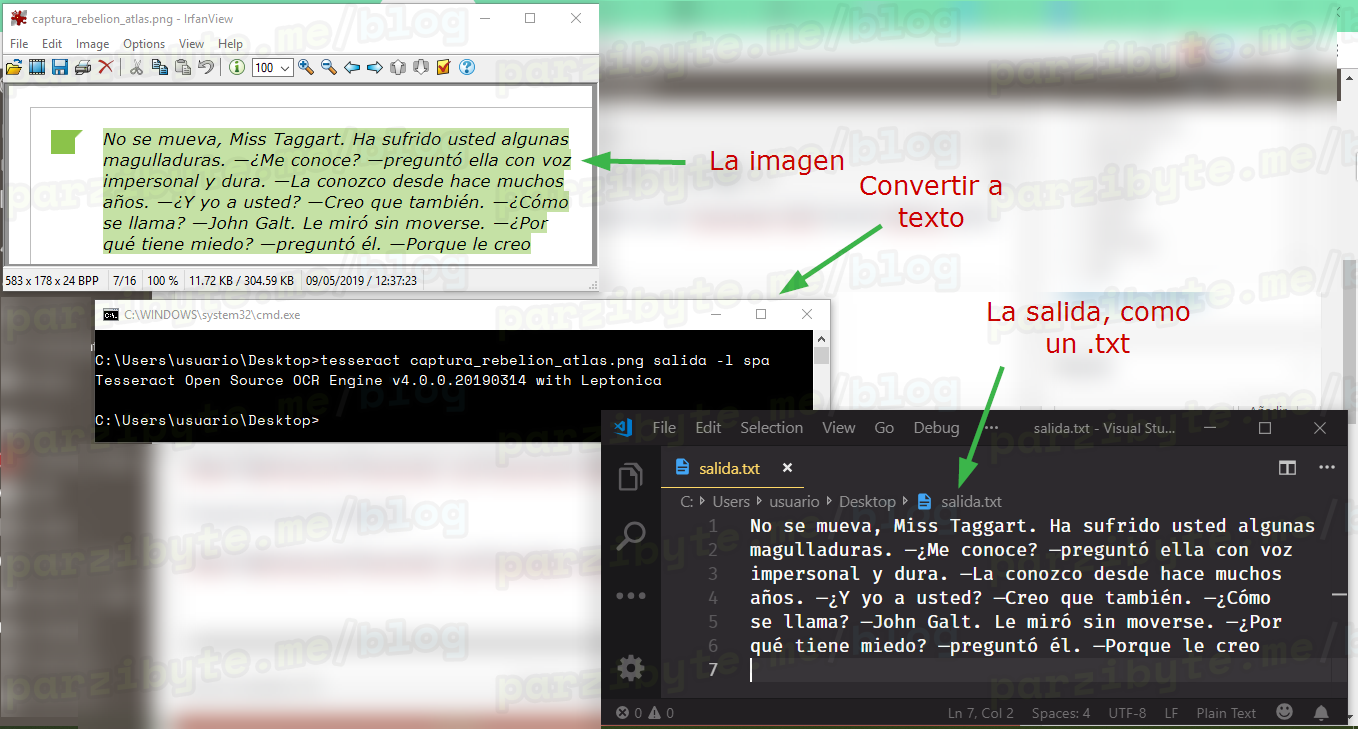
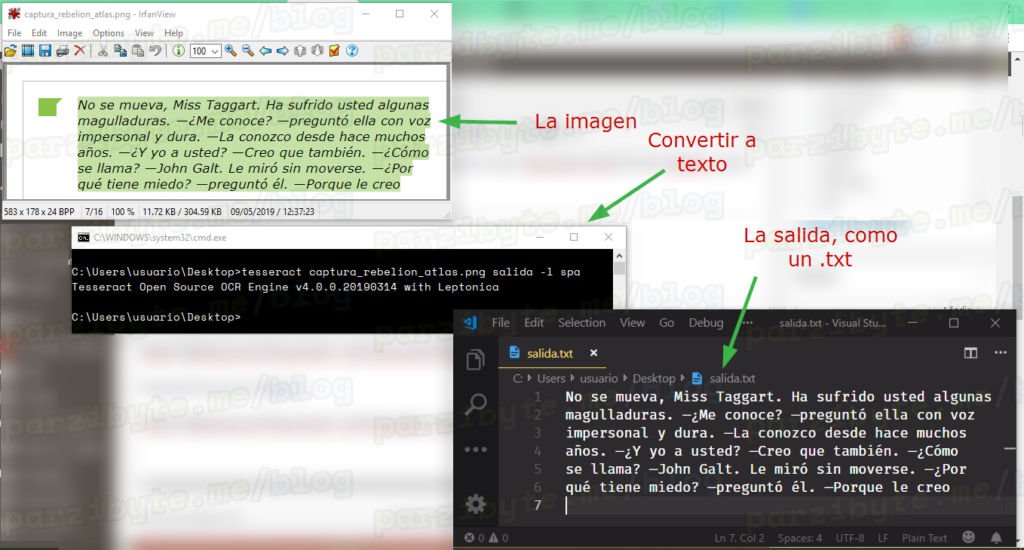
Cabe mencionar que la captura es de una nota que tomé del libro La rebelión de Atlas cuando Dagny conoce, al fin, a John Galt.
Sintaxis básica de Tesseract OCR
Lo digo de nuevo, si no has instalado Tesseract ya escribí dos posts sobre cómo instalarlo, el primero es sobre Windows y el segundo sobre Linux Ubuntu.
Ahora sí, para extraer el texto de una imagen la sintaxis es:
tesseract ruta_de_imagen ruta_de_archivo_de_salida
Por defecto toma el idioma inglés, pero podemos especificar otros con la opción -l (letra l de linux):
tesseract ruta_de_imagen ruta_de_archivo_de_salida -l spa
En esos casos pondrá el texto extraído en un archivo txt cuyo nombre especificamos, pero podemos pasar el valor de stdout para que lo imprima directamente en la consola:
tesseract ruta_de_imagen stdout -l spa
Ah, para que detecte varios idiomas hay que separarlos con un signo de más:
tesseract ruta_de_imagen stdout -l spa+eng
En el ejemplo de arriba detectaría español e inglés.
Ya he explicado la sintaxis básica, es momento de ver algunos maravillosos ejemplos de la digitalización de imágenes con Tesseract OCR.
Nota: si quieres investigar todas las opciones mira este enlace.
Ejemplos de reconocimiento de texto en imágenes con Tesseract OCR
Ya lo dije anteriormente: este maravilloso motor hace muy bien su trabajo. En las capturas de pantalla pondré la imagen, el comando y el texto resultante.
Comencemos viendo cómo extrae el texto de una portada de un libro, el libro en cuestión es El principito.
El comando es tesseract el_principito.jpg salida -l spa
Eso puso el texto en el archivo salida.txt, el cual es bastante acertado:
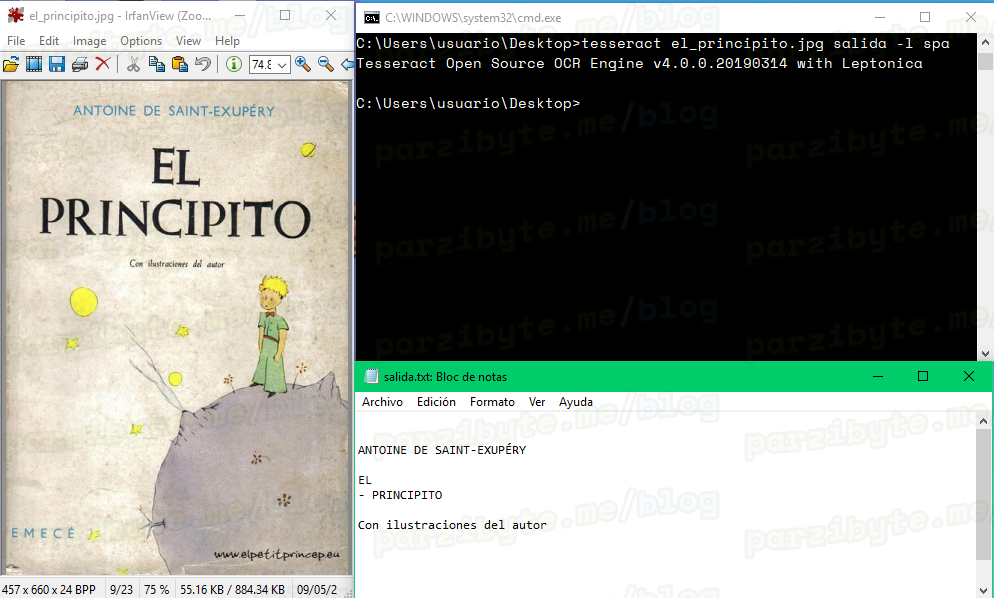
De hecho ni siquiera yo alcanzaba a ver que dice “Con ilustraciones del autor”. Ahora veamos otro ejemplo, con una captura de pantalla de la Wikipedia:
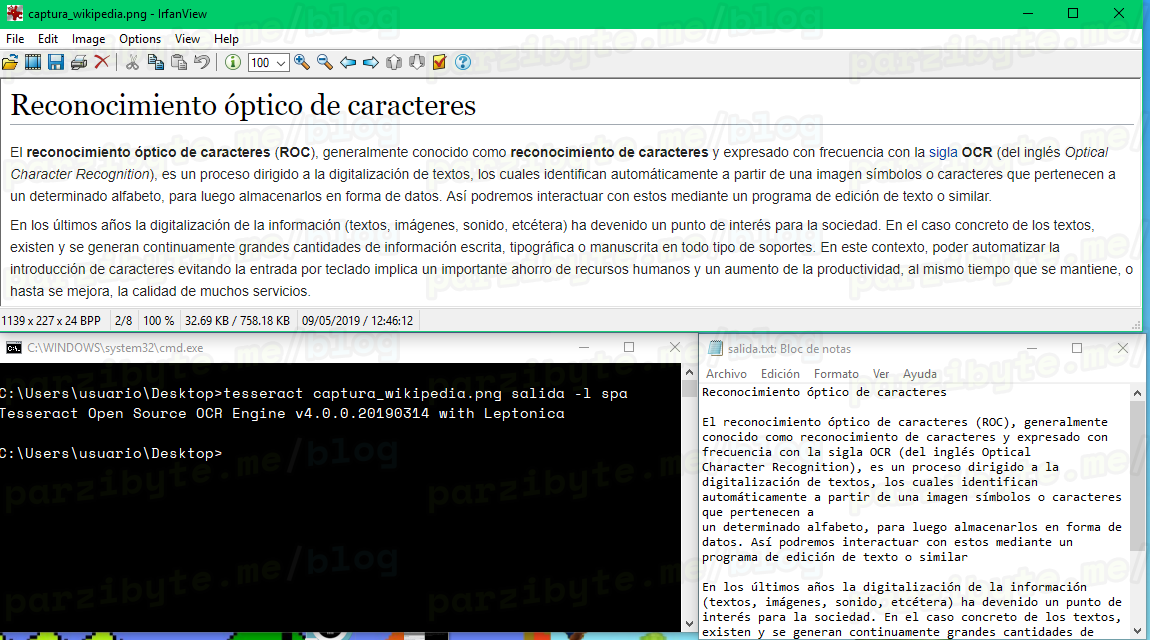
Igualmente ha reconocido el texto en la imagen aunque la tipografía cambia o hay distintos estilos de texto.
Otro ejemplo es una captura de mi blog, específicamente en el post sobre el texto a voz en JavaScript:

Lo hago para demostrar que efectivamente extra el texto aunque la tipografía o los colores cambian.
Hasta el momento lo hemos tenido fácil, ¿qué tal si probamos escanear el texto de una foto?
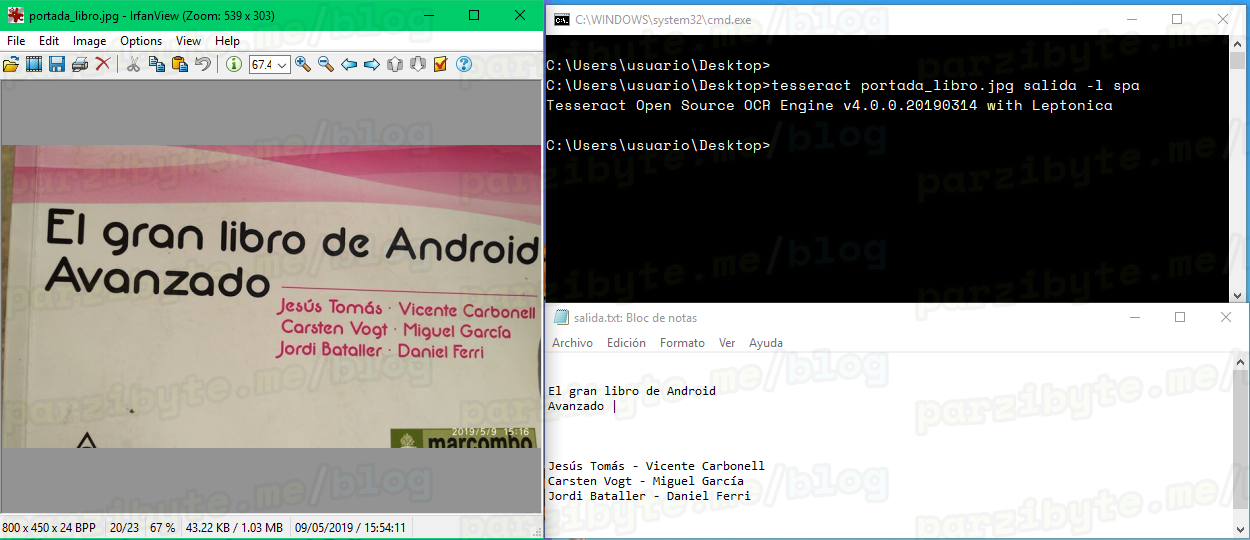
La foto no está tan bien alineada ni recortada, pero el texto ha sido detectado.
Extracción de texto de imágenes con Ubuntu
Hasta ahora todos los ejemplos han sido probados con Windows, pero con Linux Ubuntu funcionan de la misma manera:
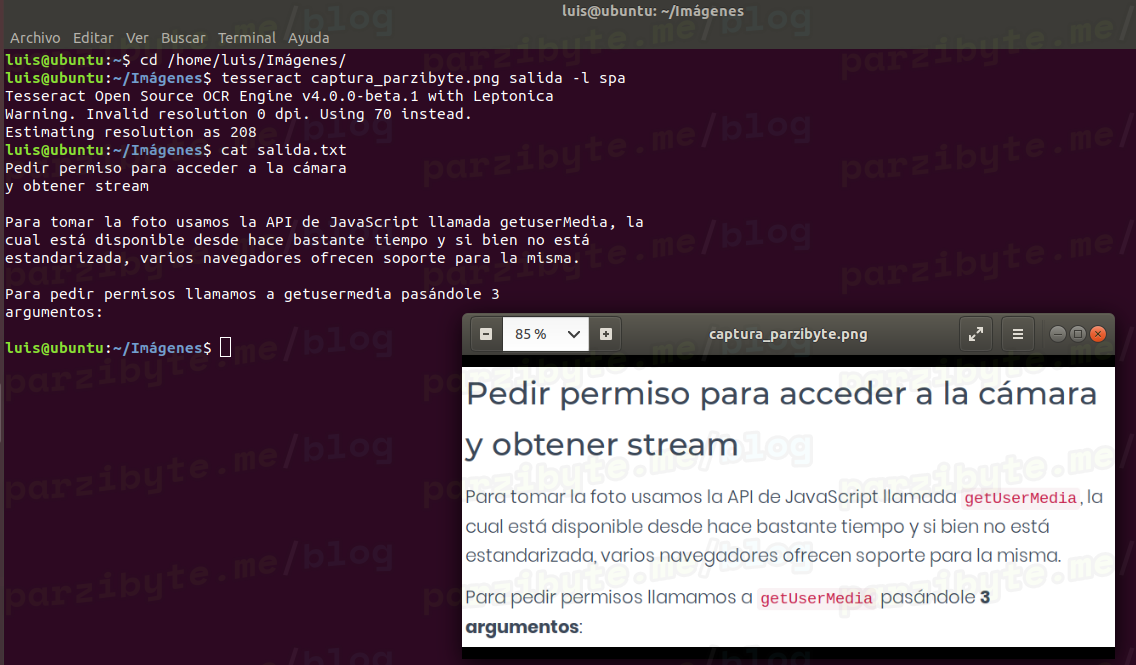
Esto es gracias a que Tesseract es multiplataforma y se comporta de la misma manera en distintos sistemas operativos.
Por si te lo preguntas, la captura es de mi blog y es sobre el post para tomar una foto con JavaScript.
Conclusión
El uso de OCR tiene bastantes aplicaciones, el más básico es convertir un escaneo a texto plano e indexable, así como la digitalización de información que está en papel.
Muchas empresas tienen información en documentos impresos pero al implementar un sistema de información se necesita tener esos registros, ahora eso ya no será un problema porque los motores OCR se encargan de extraer el texto.
Claro que todo esto no es el final, pues todavía falta ver cómo llamar a tesseract desde algunos lenguajes de programación y mejorar la detección a través de los mismos: por ejemplo, podríamos convertir una imagen a blanco y negro para que Tesseract detecte el texto de mejor manera.

¿Como hiciste para que reconozca caracteres acentuados? ¿Será que tus imagenes están a alta resolucion? Yo he usado el diccionario en español (-l spa) y spa.traineddata pero no puedo hacer un reconocimiento correcto cuando existen caracteres acentuados.
Genial artículo. Bendiciones!
Gracias, igualmente
Yo, un ser humano de este planeta (por ahora vivo)… solo quiero decirte que eres un crack, sigue avanzando, lo estás haciendo bien y es un plus que conozcas a Ayn Rand.
Gracias por sus comentarios. Saludos y éxito!
Pingback: Reconocimiento óptico de caracteres con JavaScript y Tesseract.js - Parzibyte's blog