En este post de programación en PHP te mostraré cómo extraer el texto de imágenes o mejor dicho cómo usar Tesseract OCR desde este lenguaje, de modo que podamos digitalizar el texto de una imagen usando PHP.
Al final esto que te muestro es un simple wrapper o una envoltura, ya que si bien vamos a procesar la imagen con PHP, internamente vamos a invocar a Tesseract.
Pero bueno, al final veremos cómo usar OCR con PHP para extraer el texto de imágenes. Obviamente te voy a dejar el ejemplo de código.
Sobre Tesseract
Ya he hecho un post de cómo instalar Tesseract en Windows y en Linux, así como el modo de usarlo desde la línea de comandos. La única diferencia es que ahora vamos a usar PHP para detectar texto en imágenes.
Lo que necesitamos por ahora es que puedas invocar a Tesseract desde la línea de comandos. Para comprobar que todo va bien, ejecuta:
tesseract --version
Y si la salida es similar a la siguiente, puedes continuar. En caso contrario, revisa que hayas instalado correctamente y agregado a la PATH como en los tutoriales que ya dejé anteriormente.
tesseract 4.0.0-beta.1
leptonica-1.75.3
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.2) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0
Found SSENota: en este ejemplo voy a correr el script en Linux, específicamente en Elementary OS. Si tú quieres usar esto en Windows ajusta el archivo de salida (stdout) y especifica el debug_file en otro archivo (incluso puede ser un archivo temporal).
Formulario de imagen con PHP
Es momento de pasar a la programación con PHP para detectar el texto de la imagen. Primero veamos un poco de HTML que será el formulario, mismo que va a solicitar una imagen del usuario y luego va a mostrar el texto detectado.
El formulario queda como a continuación, muy parecido al ejemplo de subir un archivo con PHP.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>OCR con PHP</title>
</head>
<body>
<h2>Selecciona una imagen:</h2>
<form action="procesar.php" enctype="multipart/form-data" method="POST">
<input type="file" name="imagen" required>
<br>
<br>
<button type="submit">Enviar</button>
</form>
</body>
</html>Fíjate en que la imagen será enviada a procesar.php, con el nombre imagen. Ya en ese script de PHP podremos acceder a la misma a través de $_FILES.
OCR con PHP
Veamos la parte del procesamiento. Necesitamos la ubicación de la imagen de la cual vamos a extraer el texto desde PHP.
Afortunadamente con PHP ya tendremos la imagen en una ubicación temporal a la cual podemos acceder a través de tmp_name.
<?php
if (!isset($_FILES["imagen"])) {
exit("No hay imagen");
}
$imagen = $_FILES["imagen"];
$ubicacionImagen = $imagen["tmp_name"];
$comando = "tesseract " . escapeshellarg($ubicacionImagen) . " stdout -l spa -c debug_file=/dev/null";
exec($comando, $textoDetectado, $codigoSalida);
if ($codigoSalida === 0) {
echo "El texto detectado es: ";
// Tenemos el texto como un array, podemos unirlo
$textoComoCadena = join("\n", $textoDetectado);
echo "<pre>";
echo $textoComoCadena;
echo "</pre>";
} else {
echo "Error detectando texto. Por favor verifique que la imagen existe y que el programa de detección está instalado y es accesible desde PHP. El código de salida es: " . $codigoSalida;
}
Lo único que falta es invocar a tesseract desde PHP, y para ello podemos usar exec. Finalmente debemos recoger el código de salida, y la salida en sí, para presentarla al usuario (aquí podríamos guardarla en una base de datos o algo similar).
Por cierto, en caso de que no lo hayas notado, la invocación a tesseract está en la línea 7 y 8.
Poniendo todo junto
Es momento de ver esto en ejecución. Seleccionamos una imagen con el formulario. La imagen que seleccioné para extraer el texto con PHP es la que se ve igualmente en la captura:
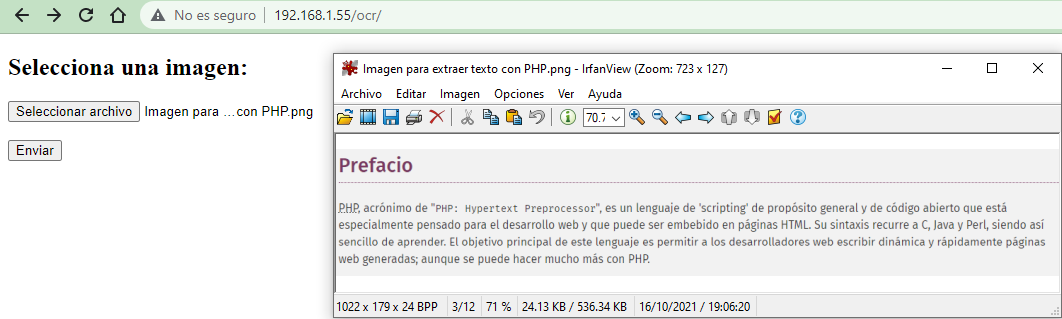
Y ahora dependiendo de qué tan rápida sea nuestra computadora o servidor, el proceso puede tardar más o menos. Al final nos presentará el texto extraído gracias a Tesseract:
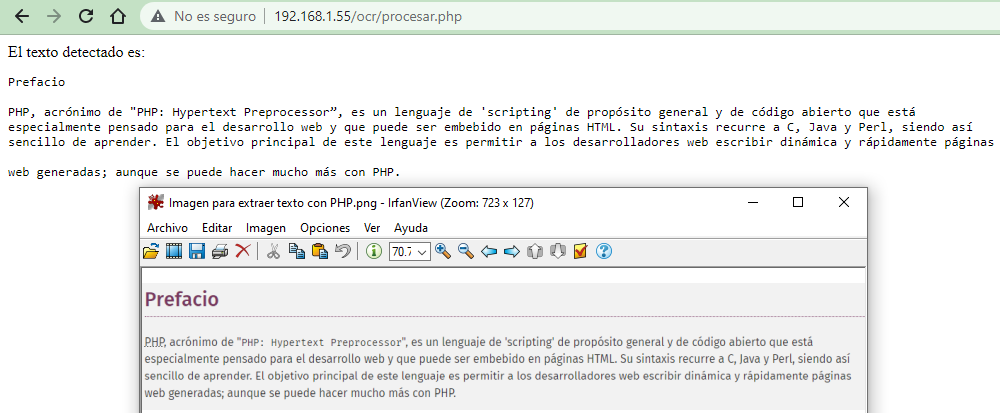
Esto fue un ejemplo muy simple de cómo combinar PHP con Tesseract para detectar y extraer el texto de una imagen. Obviamente podemos mejorar la interfaz, hacer una API, guardar el texto en una base de datos y cualquier cosa que se nos ocurra.
Para terminar el post, te dejo con más tutoriales de PHP.

” ajusta el archivo de salida (stdout) y especifica el debug_file en otro archivo ”
como se realiza eso ¿?
Hola. Gracias por sus comentarios. Si tiene alguna consulta, solicitud de creación de un programa o solicitud de cambio de software estoy para servirle en https://parzibyte.me/#contacto
Saludos!