Introducción
Vamos a ver hoy cómo replicar una base de datos en MySQL entre dos servidores. Esto es llamado replicación en MySQL. Veremos cómo sincronizar dos bases de datos de forma bidireccional, es decir, que ambos servidores sean esclavos y maestros al mismo tiempo.
En este ejemplo se hace una replicación bidireccional de una base de datos, es decir, ambos son maestros y esclavos.
Este tutorial está hecho en Windows con XAMPP y Ubuntu Server 18.04 pero funcionará perfectamente para cualquier otro sistema operativo en donde podamos instalar el motor de MySQL; ya que lo único que cambia es la ubicación del archivo de configuración llamado my.cnf o my.ini, y puedes ver en dónde se encuentra en el apartado de requisitos.
Podemos, por ejemplo, sincronizar MySQL entre dos servidores Linux. O entre dos servidores Windows, o uno Windows y otro Linux.
Resumen
Si crees que no necesitas una instalación paso a paso puedes ver el siguiente resumen.
Antes de todo haz ping y prueba que el firewall permite pasar a MySQL.
Primero, en nuestro archivo de configuración deben estar establecidos los siguientes parámetros.
El server-id debe ser distinto por cada servidor. El log_error y el log-bin pueden quedarse como se ven a continuación.
El parámetro binlog_do_db indica cuál base de datos hay que sincronizar
server-id = 50
log_error = "mysql_error.log"
binlog_do_db = tienda_db
log-bin=log-bin.logAdicionalmente en Linux debemos poner el parámetro de bind-address con la dirección del propio servidor local:
bind-address=192.168.1.68
El el maestro creamos un usuario que se encargará de replicar, obviamente cambiando nombres y contraseñas:
GRANT REPLICATION SLAVE ON *.*
TO esclavo IDENTIFIED BY '12345';
FLUSH PRIVILEGES;Desde el esclavo probamos la conexión con el usuario creado anteriormente, utilizando:
mysql -u esclavo -p -h 192.168.1.65
Si todo va bien, exporta la base de datos del maestro:
mysqldump -u root -p mascotas > ruta/al/archivo.sql
Cópiala al esclavo e impórtala. Luego en el master ejecuta:
SHOW MASTER STATUS;
Eso te dará unos parámetros como File y Position. Guárdalos o anótalos por ahí.
En el esclavo ejecuta:
CHANGE MASTER TO MASTER_HOST='192.168.1.68',
MASTER_USER='luis',
MASTER_PASSWORD='123',
MASTER_LOG_FILE='log-bin.000002',
MASTER_LOG_POS= 154;Cambiando respectivamente el valor que te dio en File y Position, así como el usuario, contraseña y host. MASTER_LOG_FILE corresponde a lo que salió en File, y MASTER_LOG_POS a lo que salió en Position.
Luego en el mismo esclavo ejecuta:
START SLAVE;
Y comprueba que todo va bien con:
SHOW SLAVE STATUS\G
En el mensaje, el apartado que dice Slave_IO_Running debe estar en Yes, al igual que Slave_SQL_Running.
Por otro lado, el que dice Slave_IO_State debe decir Waiting for master to send event.
En caso de que diga así, lo has logrado, has replicado una base de datos. Para hacerla bidireccional repite el proceso cambiando los servidores.
Si quieres ver paso por paso, explicando cada cosa, continúa leyendo.
Vídeo
He grabado un videotutorial que sirve como complemento a este tutorial, y viceversa. Si lo vas a seguir, lee la descripción del mismo.
Requisitos previos
Debe haber un archivo de configuración de MySQL, pues ese es el que vamos a editar. Si tienes XAMPP o simplemente no sabes en dónde está visita:
¿En dónde está my.cnf o my.ini?
También debes saber trabajar con la CLI de MySQL. Recomiendo visitar:
Primeros pasos con la línea de comandos de MySQL
Permitir (en el caso de Windows) que el ejecutable mysql.exe y mysqld.exe pasen a través del Firewall. Normalmente están en la carpeta llamada bin dentro de la ruta en donde instalamos MySQL.
También recomiendo resetear estados de maestros y esclavos (eso en caso de que no tengamos replicaciones ya haciéndose) con:
RESET SLAVE ALL;
RESET MASTER;
Cómo funciona la replicación en MySQL
Bueno, esta replicación es de maestro a esclavo. Es decir, configuramos un maestro y luego un esclavo se conectará a él. Los cambios que se hagan en el master se van a reflejar en el slave.
Pero, los datos que se hagan en el slave no se reflejarán en el master.
Si queremos que sea una replicación bidireccional, o de ambos lados, es hacer lo mismo. Es decir, tenemos 2 servidores: A y B
- Configuramos el A como maestro y el B como esclavo. Ahora el B se conecta al A y baja todos los cambios.
- Configuramos también el B como maestro y el A como esclavo. Ahora el A se conecta al B y baja todos los cambios.
De esta manera ambos son maestros y esclavos al mismo tiempo, haciendo así una sincronización o replicación en MySQL de una forma bidireccional.
Probar conexión
Antes de empezar todo esto tenemos que comprobar que ambas máquinas tienen conexión entre sí. Eso lo podemos hacer con el comando ping seguido de la IP. Así:
ping 192.168.1.171
Eso suponiendo que la IP es 192.168.1.171. Si no hay conexión, debemos comprobar que ambos servidores estén en la misma red y todo eso. No sigas leyendo si no hay conexión.
Configurar maestro
Comenzamos por aquí, vamos a configurar nuestro servidor maestro para que acepte conexiones y todas esas cosas. Abrimos el archivo de configuración y editamos, agregamos o descomentamos cada línea según el paso.
¿Qué es descomentar? bueno, algunas líneas comienzan con el signo #. Ese signo comenta la línea. Por ejemplo aquí hay una que dice así:
# bind-address="127.0.0.1"
Descomentada quedaría así:
bind-address="127.0.0.1"
Ese es un ejemplo, no tenemos que cambiar esa línea.
Paso 1: configurar el ID del servidor
Cada servidor debe tener un ID distinto para que, valga la redundancia, lo identifique ante los otros. Cada uno de ellos tiene un ID por defecto pero si lo dejamos así, va a chocar con otro.
Entonces buscamos en nuestro archivo de configuración la parte en donde dice server-id. Puede que haya dos líneas que digan lo mismo, con descomentar una basta:

En mi caso puse el server-id en 28. Es un número que puede ir desde 1 hasta (2 elevado a la 32) menos 1; esto es 4294967295. Podemos poner el que queramos, siempre y cuando pongamos uno distinto en el otro servidor.
Aplicamos cambios, reiniciamos y nos logueamos en la CLI como usuario root(ve el tutorial de arriba si no sabes cómo). Luego ejecutamos la siguiente consulta:
SHOW VARIABLES LIKE 'server_id';Lo que nos debe dar el número que configuramos en el archivo de configuración. Esto es más que nada para verificar que los cambios que hacemos en el archivo se reflejan al iniciar el server. En mi caso sale esto:

El número 28, justo como lo configuré. Si no sale el mismo número que configuramos en el archivo debemos checar que estamos editando el fichero correcto, hemos guardado y que reiniciamos el servidor.
Paso 2: configurar log y base de datos que vamos a replicar
Es momento de ajustar otras 2 opciones. La primera es el log, así que vamos y descomentamos (o agregamos si no existe) la línea que dice log-bin y la establecemos en mysql-bin.log así:
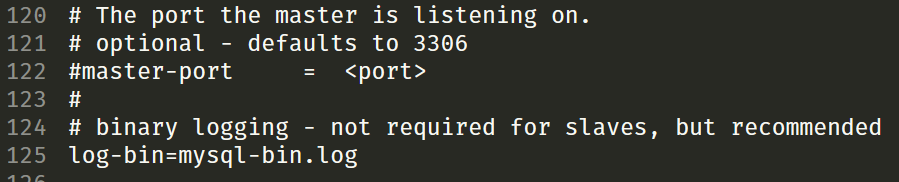
Y con eso tenemos. Ahora vamos a indicar cuál base de datos se va a replicar. En mi caso tengo que hacerlo con una que se llama “tienda_db” así que agrego la siguiente línea en la sección de mysqld.
Esta línea por defecto no viene, hay que agregarla en la sección de mysqld. Así:
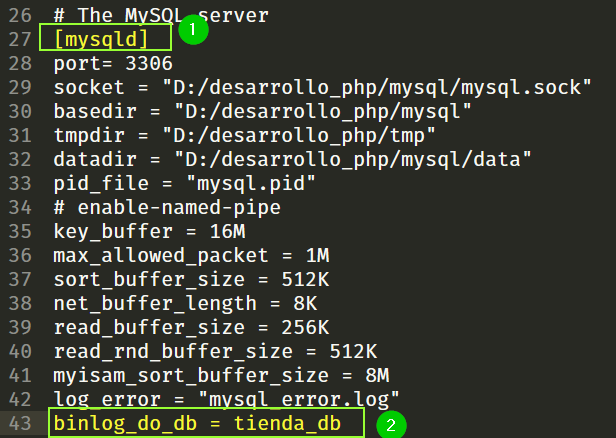
La sección es la que dice [mysqld] y hasta abajo de todas las líneas ponemos la que dije hace un momento.
Si quisiéramos replicar más bases de datos, agregaríamos más líneas de esas. Es decir, en lugar de:
binlog_do_db = tienda_db
Se vería así:
binlog_do_db = tienda_db
binlog_do_db = mascotas
binlog_do_db = videojuegos
binlog_do_db = otra_dbAhí replicaríamos tienda_db, mascotas, videojuegos y otra_db.
Después de esto igualmente guardamos cambios y reiniciamos el servidor.
Paso 2.1 sólo en Linux
Si estás replicando en Linux, debes poner o descomentar la opción que dice bind-address y ponerla en la IP del servidor. Aquí un ejemplo:

En ese caso puse el id de servidor a 123 y la bind-address a 192.168.1.68 pues esa es la IP del propio servidor. Los demás parámetros como binlog_do_db y log-bin se quedan como lo vimos en los otros apartados.
Paso 3: crear usuario y darle permiso de ser esclavo
Nos logueamos de nuevo en la CLI de MySQL y ejecutamos el siguiente comando:
GRANT REPLICATION SLAVE
ON *.*
TO esclavo
IDENTIFIED BY '25k8qzRcgh22K943';Dos cosas importantes. La primera es que el usuario se llama “esclavo”. Podríamos ponerle otro nombre, siempre y cuando lo recordemos.
La segunda es la contraseña, la cual siempre debe ser segura y debe ir entre comillas simples ‘. Obviamente no estamos obligados a usar esa contraseña, es un ejemplo. Y si vamos a probar pues podemos poner “123” o cosas de esas.
Lo ejecutamos:
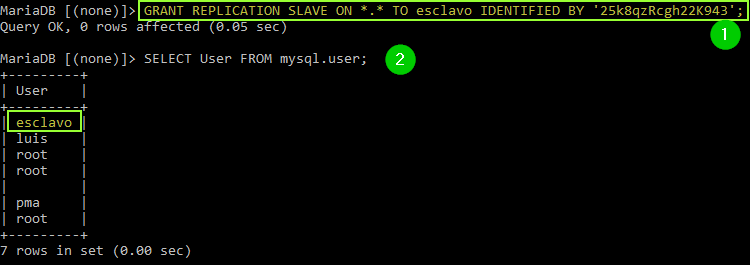
Para comprobar que el usuario fue creado podemos ejecutar:
SELECT User FROM mysql.user;Lo que nos dará una lista como la que se ve en la imagen. Finalmente ejecutamos:
FLUSH PRIVILEGES;
Paso 4: probar conexión de esclavo
Ahora nos vamos un momento a nuestro server que será esclavo, no vamos a configurar nada todavía, simplemente comprobaremos que tenemos conexión y que nuestro usuario se puede loguear.
Entonces en el esclavo (en la terminal o consola del servidor) ejecutamos:
mysql -u esclavo -p -h 192.168.1.171Ahí nos estamos logueando a un host distinto. En mi caso la ip es 192.168.1.171, en tu servidor obviamente cambiará. Si todo va bien, nos pedirá la contraseña y nos dará la bienvenida:
Si nos da un error, por favor permite que el firewall deje pasar las conexiones de MySQL. Este problema viene especialmente en Windows, aunque igual y se presenta en Linux.
En mi caso lo probé desde Ubuntu Server 18.04:

Como vemos, en el argumento h pasamos la ip del host. En el argumento u pasamos el nombre de usuario y dejamos vacío el argumento p para que se nos pregunte la contraseña. Luego de eso nos dará la bienvenida, lo que significa que sí hay conexión.
Paso 4: crear base de datos en esclavo
Las bases de datos se van a sincronizar, sí. Pero no se van a crear automáticamente. Lo que tenemos que hacer es, en el esclavo, crear la base de datos:

Si sincronizamos más bases de datos, las creamos una por una. Para crear las tablas y todo eso veremos el paso 5
Paso 5: importar y exportar base de datos
La replicación no comenzará desde 0, tenemos que mandarle algunos datos antes. Es decir, si nuestra base de datos está vacía no habrá problemas, pero los datos ya existentes no se replicarán la primera vez.
Por ello hay que exportar la base de datos en el maestro, y luego importarla en el esclavo. La exportamos así:
mysqldump -u root -p tienda_db > C:\Users\luis\Desktop\tienda_db.sqlEn lugar de ejecutar mysql, ejecutamos mysqldump. Le pasamos igualmente el usuario y la contraseña, pero aparte el nombre de la base de datos. Luego usamos el operador > para redireccionar la salida a (en mi caso) el escritorio.
Copiamos ese archivo al servidor esclavo y ahí ejecutamos:
mysql -u root -p tienda_db < ruta/en/donde/esta/el/archivo/de/exportacion.sqlComo vemos ahora usamos < en lugar de >. De ahí es como si nos hubiéramos logueado normalmente, pero ahora seleccionamos la base de datos.
Lo que haré esto es copiar los datos exportados al esclavo. En mi caso se ve así:

En el paso 1 ejecuto el comando para importar. En el paso 2 me logueo normalmente para comprobar que las tablas existen, con el comando del paso 3.
Nota: el comando sudo no es necesario si estamos en Windows, ya deberías saberlo.
Volvemos a nuestro servidor maestro y ahora sí empezamos la replicación.
Paso 6: mostrar estado del maestro
La replicación debe saber en qué punto se encuentra, cuál es el avance y todo ello. Para ser esclavos necesitamos primero ver el estado del maestro, entonces en el master ejecutamos:
SHOW MASTER STATUS;
Lo que dará una salida parecida a esta:
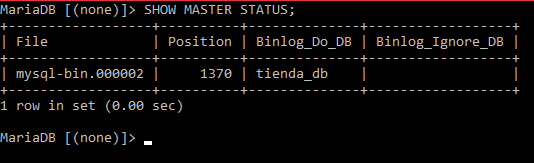 Es importante tener a la mano esos datos, o anotarlos, o como se le diga. Vemos que el archivo está en mysql-bin.000002, la posición es 1370 y la base de datos es tienda_db.
Es importante tener a la mano esos datos, o anotarlos, o como se le diga. Vemos que el archivo está en mysql-bin.000002, la posición es 1370 y la base de datos es tienda_db.
Todo bien, ahora vamos al esclavo.
Paso 7: replicar desde el esclavo
Ya este es el último paso. Vamos al esclavo, nos logueamos en MySQL (si es que no estamo logueados ) y escribimos:
CHANGE MASTER TO
MASTER_HOST='192.168.1.171',
MASTER_USER='esclavo',
MASTER_PASSWORD='25k8qzRcgh22K943',
MASTER_LOG_FILE='mysql-bin.000002',
MASTER_LOG_POS= 1370;Eso lo pegamos todo junto, es un único comando. Algunas cosas que hay que notar es que escribimos el host, o sea la IP de nuestro servidor, también el usuario que es esclavo, la contraseña y finalmente dos cosas importantes:
- El archivo es mysql-bin.000002 justo como decía el maestro allá arriba.
- La posición es 1370, debemos poner el número que dijo el maestro allá arriba.
Lo ejecutamos, y más tarde ponemos esto:
START SLAVE;
Finalmente comprobamos si todo va bien con el siguiente comando:
SHOW SLAVE STATUS\G
El \G es un viejo truco que hace que la salida sea en vertical en lugar de horizontal. Aquí un pequeño GIF de todo eso:

Si observamos bien, cada cambio hecho en el maestro es replicado al esclavo. Por ejemplo, hacemos un insert en el maestro y al hacer un select en el esclavo los cambios se reflejan. Al igual que al eliminar y al actualizar.
Para replicar de ambos lados seguimos los mismos pasos pero invertimos los servidores.

Un cordial saludo, excelente este tutorial, pero como se podría hacer con tres o mas servidores? gracias
Hola. Gracias por sus comentarios. Si tiene alguna consulta o duda, solicitud de creación de un programa, solicitud de vídeo o solicitud de cambio de software estoy para servirle en https://parzibyte.me/#contacto
Saludos!
Gracias por la información.
Pingback: Respaldar base de datos de MySQL automáticamente usando cron en Ubuntu - Parzibyte's blog