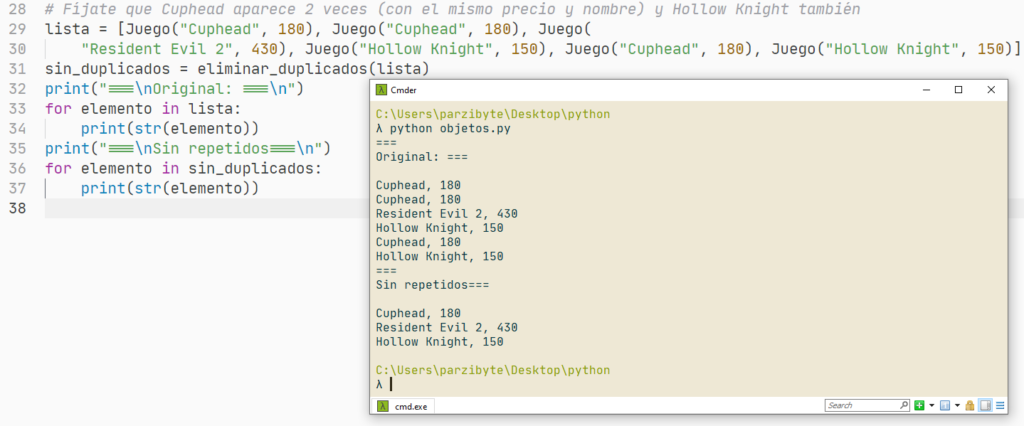
Python – Eliminar repetidos de lista
En este post vamos a ver cómo eliminar los elementos duplicados de un arreglo, array o lista usando el lenguaje de programación Python. Al final vamos a definir una función que recibirá una lista que puede tener elementos repetidos pero siempre devolverá un arreglo sin los repetidos, sin importar si los datos son primitivos u […]
Python – Eliminar repetidos de lista Leer más »