En este tutorial de Python veremos cómo convertir las páginas de un PDF a imagen, convirtiendo cada página del documento a una imagen y guardándola en el almacenamiento, indicando la resolución.
No vamos a extraer cómo extraer las imágenes del PDF, vamos a convertir las páginas de un PDF a imágenes con Python. Para esto vamos a usar pypdfium, un paquete de Python que es una vinculación de PDFium.
Instalando pypdfium
Vas a necesitar Python y pip. Una vez que tengas a pip.exe y python.exe en la path, ejecuta:
python -m pip install -U pypdfium2
PDF de ejemplo
Para demostrar el funcionamiento de este script de Python que convierte un PDF a imagen voy a usar un PDF que se basa en mi post de recetario, pero toma en cuenta que esto va a funcionar con cualquier PDF.
Convertir PDF a imagen con Python
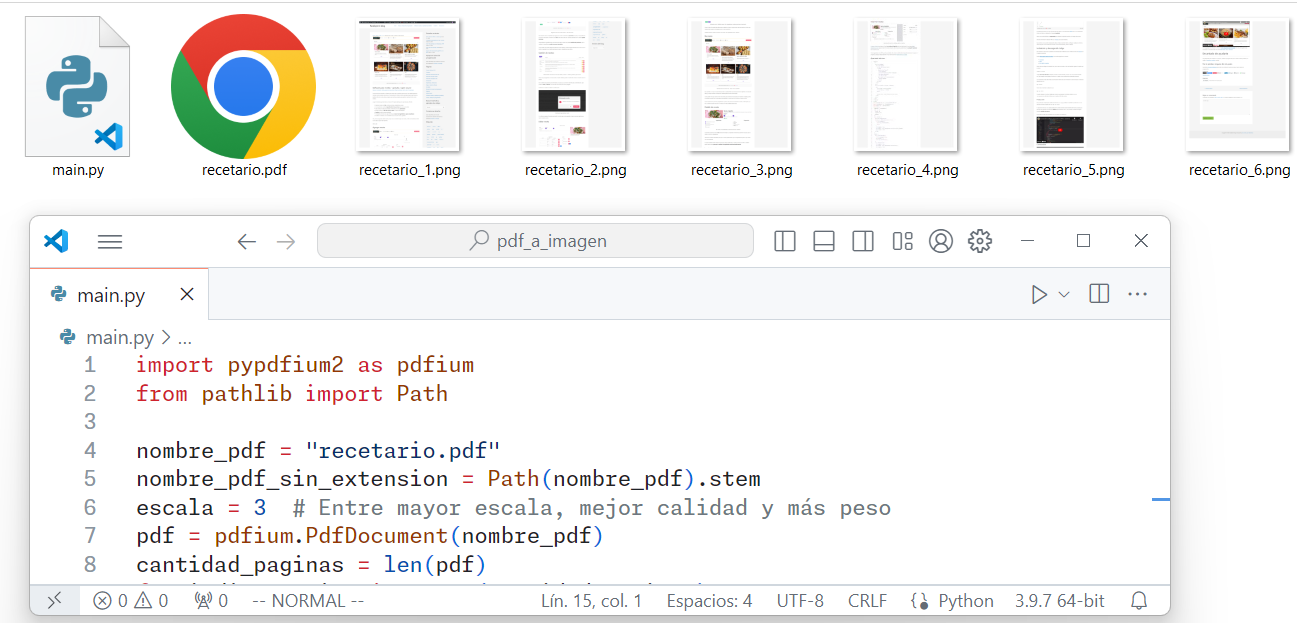
Ahora veamos el script de Python. Lo que el código hace es:
- Abrir el PDF según su ubicación, usando
pdfium.PdfDocument - Obtener el nombre del PDF sin extensión, para que las imágenes de salida tengan el mismo nombre del PDF
- Recorrer las páginas del PDF, renderizar cada página según la escala y guardarla en el almacenamiento
- Guardar cada imagen con el mismo nombre que el PDF, agregando el número de página al final
El código queda como se ve a continuación:
import pypdfium2 as pdfium
from pathlib import Path
nombre_pdf = "recetario.pdf"
nombre_pdf_sin_extension = Path(nombre_pdf).stem
escala = 3 # Entre mayor escala, mejor calidad y más peso
pdf = pdfium.PdfDocument(nombre_pdf)
cantidad_paginas = len(pdf)
for indice_pagina in range(cantidad_paginas):
numero_pagina = indice_pagina+1
print(f"Extrayendo página {numero_pagina} de {cantidad_paginas}")
pagina = pdf.get_page(indice_pagina)
imagen_para_pil = pagina.render(scale=escala).to_pil()
imagen_para_pil.save(f"{nombre_pdf_sin_extension}_{numero_pagina}.png")
Al ejecutarlo, suponiendo que el PDF existe, se van a extraer las páginas como imagen. En cuanto a la escala:
- Por defecto es 1
- Se recomienda que sea 4.16
- Entre más grande, mejor calidad de imagen, pero mayor peso
Una vez que tengamos las páginas del PDF separadas con Python podemos rotarlas, modificarlas o comprimirlas y más adelante convertir esas imágenes en un PDF.
