Resumen: mostrar cómo usar la API de reconocimiento de voz (webkitSpeechRecognition) con JavaScript, de tal manera que el navegador pueda entender nuestra voz y pueda transcribirla (es decir, convertir voz a texto).
Me emociona hacer otro tutorial sobre las API de JS. Ya vimos cómo tomar una foto, grabar un vídeo, grabar audio o convertir texto a voz.
Ahora voy a mostrarte cómo usar el reconocimiento de voz en la web con JavaScript, de una manera fácil.
Compatibilidad de webkitSpeechRecognition
Por ahora esta API está disponible para Chrome tanto en escritorio como en móvil de Android pero si en el futuro se agrega a otros navegadores, actualizaré el post.
Primer vistazo al reconocimiento de voz con JS
Veamos un primer ejemplo. Lo único que tenemos que hacer es crear una instancia de webkitSpeechRecognition:
let sr = new webkitSpeechRecognition();
Ahora debemos definir una función cuando haya resultados, para ello agregamos una función a onresult de nuestro objeto recién creado, así:
Este método de onresult se va a estar invocando cada que se detecte que el usuario comienza y termina de hablar, es decir, que dice una frase u oración.
Por el momento solo estamos imprimiendo los resultados. Finalmente iniciamos el reconocimiento de voz en la web con:
sr.start();
Así que todo queda así:
Al probarlo obviamente se nos va a pedir permiso para acceder al micrófono:

Después debemos hablar y en la consola se imprimirán los resultados:
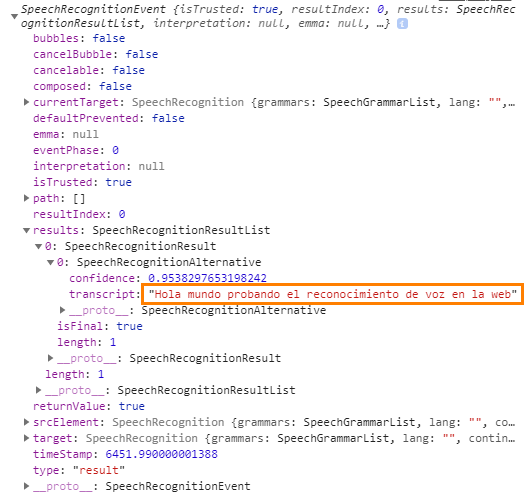
Lo que realmente nos interesa para obtener la transcripción de voz a texto es la propiedad results, que es un arreglo que tiene otros arreglos. Normalmente vamos a acceder al último elemento del arreglo en la posición 0 y luego a transcript, pues es lo último que se escuchó pero ahora en forma de texto.
Si quieres prueba lo que te digo en este enlace.
Evitando que se detenga el reconocimiento de voz
Cuando se detecta que ya no hay voz o algo así, el reconocimiento se pausa y ya no se inicia nunca más. Además, en Android el reconocimiento solo funciona una vez y después se detiene.
Es por ello que debemos usar un truco y es que debemos escuchar el evento que indica que se detuvo el reconocimiento, y volverlo a iniciar.
Por lo tanto queda algo así:
Escribiendo todo el texto que se reconoce
Ahora veremos la segunda parte en donde ya vamos a interactuar con HTML y haremos que cada frase detectada se escriba en el documento, para ir viendo cómo es que hacemos un “dictado en la web” usando reconocimiento de voz.
Primero definimos nuestro HTML. Vamos a colocar el texto detectado en un párrafo así que le ponemos un id para después obtener una referencia al mismo con querySelector.
Ahora vemos el script. Accedemos al último elemento del arreglo de arreglos y después al primer elemento para finalmente tener a transcript. Después, agregamos un salto de línea y el texto detectado al párrafo:
Lo he probado en mi teléfono pues el micrófono de mi portátil no es tan bueno; aquí los resultados:

Si quieres puedes probarlo aquí.
Conclusión y cosas importantes
No se puede usar el reconocimiento de voz fuera de línea u offline, pues al menos la API de webkitSpeechRecognition funciona con reconocimiento en la nube así que requiere internet.
Una vez que tenemos el texto podemos ejecutar funciones, es decir, podríamos definir comandos de voz y realizar determinada acción.
Por el momento solo funciona con Chrome; esperemos que en el futuro se agregue a más navegadores.
Sería interesante combinar esta tecnología con expresiones regulares o comandos, y el texto a voz para hacer algo como un asistente que te hable y escuche; ¡Todo en la web!
Muy pronto traeré más tutoriales sobre esto, mientras tanto te invito a suscribirte o a ver el repositorio en GitHub.
Actualización: mira cómo usar annyang para definir comandos de voz.
Estoy aquí para ayudarte 

Estoy aquí para ayudarte en todo lo que necesites. Si requieres alguna modificación en lo presentado en este post, deseas asistencia con tu tarea, proyecto o precisas desarrollar un software a medida, no dudes en contactarme. Estoy comprometido a brindarte el apoyo necesario para que logres tus objetivos. Mi correo es parzibyte(arroba)gmail.com, estoy como@parzibyte en Telegram o en mi página de contacto


