Descargar libros de CONALITEG

Descargar libro de CONALITEG con Script de Python - Descargar imágenes y convertir a PDF
Ayer alguien me preguntó si se podía descargar un libro de texto gratuito de la página de CONALITEG (Comisión Nacional de Libros de Texto Gratuitos), así que le pedí que me enviara el enlace y al entrar vi que no es un PDF.
Al analizarlo vi que es una imagen que se muestra con magazine.js y que cada que pasas de página se carga una nueva imagen en el fondo (eso lo vi solo en un vistazo rápido, así que puede que esté equivocado en las librerías o esas cosas, aunque al final no importa):
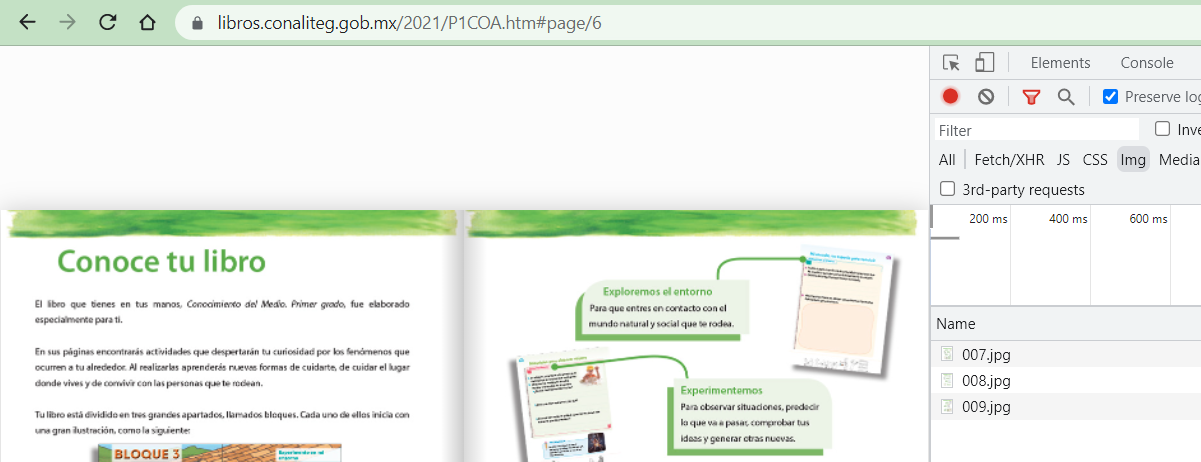
Si te fijas, las páginas van en orden, es decir, va la 001, 002, etcétera hasta el final del libro.
Entonces pensé en una idea: hacer un script de Python que reciba el número de páginas del libro, la dirección del mismo y visite todas las páginas de las imágenes, las descargue una por una y después las convierta a PDF.
Para mi sorpresa el script funcionó como un encanto, y por eso te vengo a compartir cómo descargar esos libros y tal vez otros más que usen la misma tecnología.
Aviso sobre el copyright y esas cosas
Yo creo que el conocimiento debería ser gratuito para todos, y que debería ser fácil acceder al mismo y sin internet (piensen en la gente que tiene que soportar la poca calidad del internet de telmex)
Si la página de CONALITEG no quiere que descarguemos sus libros con un script, nada les cuesta poner un botón grande y color verde que diga DESCARGAR, ¿cierto?
Yo proporciono esto por si a alguien más le sirve y para mostrar de lo que es capaz este lenguaje de programación, pero no me hago cargo si se usa para otros fines.
Me descargo de toda responsabilidad. Todo lo que hagas a partir de ahora es por tu decisión.
Analizando el comportamiento de la página
Pongamos un ejemplo: el libro de español lecturas de primer grado. Si lo quieres leer entonces puedes ir a https://libros.conaliteg.gob.mx/2021/P1LEA.htm.
Al entrar se cargará la primera página, y si le das clic derecho a la imagen y la abres en una nueva pestaña te dirige a: https://libros.conaliteg.gob.mx/2021/c/P1LEA/000.jpg
Si luego vas a https://libros.conaliteg.gob.mx/2021/c/P1LEA/001.jpg te mostrará la página 1, si vas a https://libros.conaliteg.gob.mx/2021/c/P1LEA/002.jpg te mostrará la segunda y así sucesivamente.
Este libro en cuestión tiene 128 páginas si analizamos el índice, y entonces solo tenemos que visitar 128 enlaces en donde se respeta el siguiente formato (para este libro en cuestión):
https://libros.conaliteg.gob.mx/2021/c/P1LEA/[El número de página va aquí].jpg
Pensando en el script
Ahora solo nos falta hacer un programa que descargue un libro. El mismo va a necesitar de la URL en donde solo cambia el número de página, la cantidad de páginas y el nombre del PDF para convertir todas las imágenes en un documento.
En mi blog ya te he mostrado cómo descargar una imagen con Python y cómo convertir imágenes a PDF con Python. También vamos a necesitar rellenar un número con ceros a su izquierda.
Nota: yo usé Python por su facilidad, pero técnicamente se podría hacer con cualquier lenguaje.
Descargar cualquier libro de CONALITEG
Entonces solo es cuestión de juntar todo, definir algunas funciones y listo. El código queda bastante limpio:
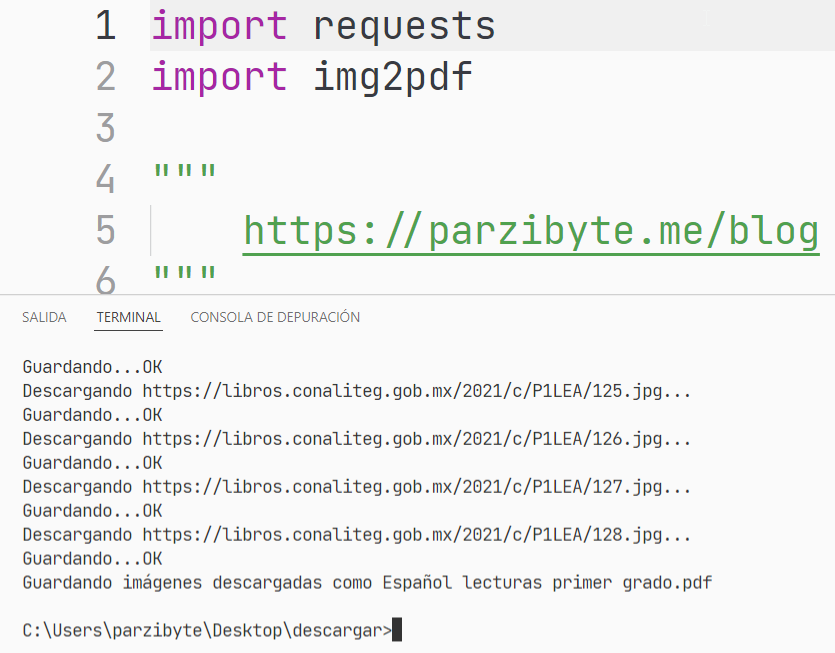
import requests
import img2pdf
"""
https://parzibyte.me/blog
"""
def descargar_imagen(url_base, nombre):
url_imagen = f"{url_base}{nombre}.jpg"
print(f"Descargando {url_imagen}...")
nombre_local_imagen = f"{nombre}.jpg"
imagen = requests.get(url_imagen).content
print("Guardando...", end="")
with open(nombre_local_imagen, 'wb') as handler:
handler.write(imagen)
print("OK")
return nombre_local_imagen
def descargar_libro(url_base, paginas, nombre_pdf):
inicio = 0
imagenes = []
for i in range(inicio, paginas+1):
numero_con_ceros_a_la_izquierda = f"{i:03d}"
nombre_imagen_descargada = descargar_imagen(
url_base, numero_con_ceros_a_la_izquierda)
imagenes.append(nombre_imagen_descargada)
with open(nombre_pdf, "wb") as documento:
print(f"Guardando imágenes descargadas como {nombre_pdf}")
documento.write(img2pdf.convert(imagenes))
descargar_libro(
"https://libros.conaliteg.gob.mx/2021/c/P1LEA/", 128, "Español lecturas primer grado.pdf")
Por cierto, para esto necesitas contar con Python y PIP. Luego instalar las dependencias de img2pdf y requests con:
pip install requests
pip install img2pdf
Cambia lo necesario al invocar a descargar_libro en la línea 34 (es decir, la URL, el número de páginas y el nombre del PDF), abre una terminal en el mismo lugar donde está el script y ejecútalo con: python descargar_libro_conaliteg.py.
Versión mejorada
Resultados
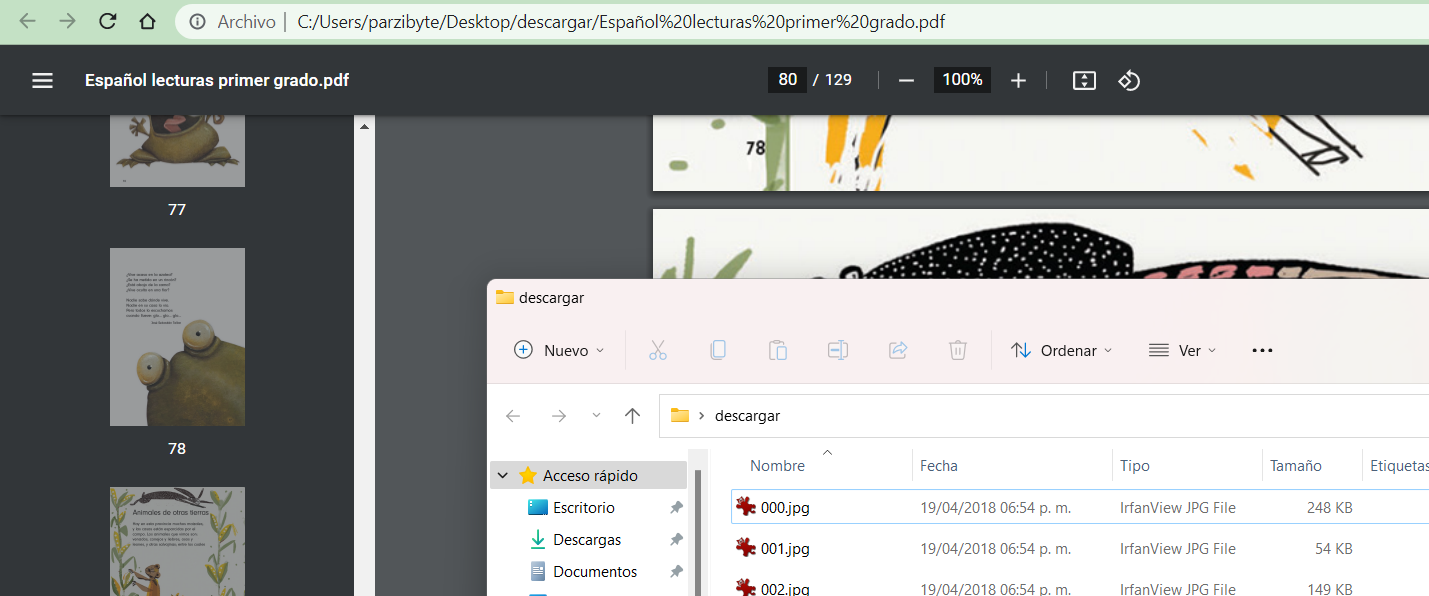
La salida al ejecutar el script ya la has visto anteriormente. Y después de que se termine de descargar, tendrás el PDF y las imágenes (ya puedes borrar las imágenes si quieres).
Al abrir el PDF se ve como un documento normal. Ya te puedes llevar ese libro a cualquier lugar y leerlo sin internet:
Conclusión y bonus
Después de hacer este script pensé en una manera de hacerlo fácil para una persona que no tiene conocimientos de programación, en donde la misma solo coloque el enlace de las imágenes del libro y un programa haga el resto.
Probé un poco y me decidí por Flask, que es un framework web de Python muy simple pero poderoso (con él pudimos acceder a una cámara, por ejemplo).
Así que en el siguiente post veremos cómo encapsular todo esto en una webapp de Flask amigable para el usuario. Mientras tanto te dejo más sobre Python.
Actualización: ya publiqué la herramienta.
Actualización 2024: hice otra herramienta que puedes ejecutar en tu computadora de manera más fácil y que funciona sin servidores. Mírala en: https://parzibyte.me/blog/2024/05/22/mejorando-descargador-libros-conaliteg/

{kind=link}
{kind=link}
{kind=link}
Entradas recientes
Resetear GOOJPRT PT-210 MTP-II (Impresora térmica)
El día de hoy vamos a ver cómo restablecer la impresora térmica GOOJPRT PT-210 a…
Proxy Android para impresora térmica ESC POS
Hoy voy a enseñarte cómo imprimir en una impresora térmica conectada por USB a una…
Android – Servidor web con servicio en segundo plano
En este post voy a enseñarte a programar un servidor web en Android asegurándonos de…
Cancelar trabajo de impresión con C++
En este post te quiero compartir un código de C++ para listar y cancelar trabajos…
Copiar bytes de Golang a JavaScript con WebAssembly
Gracias a WebAssembly podemos ejecutar código de otros lenguajes de programación desde el navegador web…
Imprimir PDF con Ghostscript en Windows de manera programada
Revisando y buscando maneras de imprimir un PDF desde la línea de comandos me encontré…