C – Extraer contenido de archivo HTML

Extraer cuerpo de archivo HTML usando ANSI C - Trabajo con cadenas
En este post de programación en C te enseñaré cómo obtener el texto (ignorando etiquetas) que se encuentra dentro de las etiquetas <body> de un archivo HTML.
Vamos a extraer lo que hay en el cuerpo de la página, pero además vamos a obtener solo el texto, ignorando todas las etiquetas que existan. Por poner un ejemplo, si la página es:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Mi página web - By Parzibyte</title>
</head>
<body>
Aquí va el contenido
<p> Soy un párrafo</p>
Yo no estoy dentro de una etiqueta <h1> Yo soy un encabezado</h1>
<strong>Ejemplo de otra etiqueta</strong>
</body>
</html>El programa en ANSI C debe extraer el contenido y además ignorar las etiquetas, produciendo la siguiente salida:
Aquí va el contenido
Soy un párrafo
Yo no estoy dentro de una etiqueta Yo soy un encabezado
Ejemplo de otra etiqueta
Veamos cómo resolver este ejercicio propuesto en C, ya que en otro lenguaje con soporte nativo de expresiones regulares sería fácil, pero aquí no lo es tanto.
Explicación del algoritmo
Vamos a dividir el problema en dos partes. Primero debemos extraer lo que hay en el cuerpo, entre las etiquetas <body> y </body>.
Para ello usamos strstr, buscamos el inicio y fin y después extraemos lo que haya entre estas etiquetas, copiándolo a una nueva cadena.
Después de eso recorremos la cadena (que será el cuerpo del documento) y si encontramos el inicio de una etiqueta (<) ignoramos los siguientes caracteres hasta que encontremos la etiqueta de cierre (>).
De este modo al final tendremos la cadena limpia en donde estará todo el HTML ya parseado. Obviamente esto ni siquiera se acerca a un parseador o intérprete, solo es un ejercicio que me pareció interesante de publicar.
Leyendo contenido y almacenando en cadena
Aunque esto no es lo más óptimo, es lo más fácil. Necesitamos almacenar todo el contenido del archivo en una cadena, así que recorremos el archivo y vamos concatenando a la cadena.
FILE *archivo;
unsigned char bufer[TAMANIO_BUFER];
archivo = fopen(nombreArchivo, "r");
if (archivo == NULL)
{
printf("Error abriendo el archivo");
return;
}
// Leer archivo
char contenido[TAMANIO_MAXIMO_CONTENIDO] = "";
while (!feof(archivo))
{
fread(bufer, sizeof(char), sizeof(bufer), archivo);
// Almacenar contenido en el búfer
strcat(contenido, bufer);
}
Cuando el código se haya ejecutado tendremos el contenido en una cadena de C.
Extrayendo body de HTML
Siguiendo con este ejercicio de C necesitamos extraer lo que se encuentra entre las etiquetas del cuerpo. Para ello simplemente usamos strstr y luego extraemos la cadena.
// Extraer lo que hay entre <body> y </body>
const char inicioEtiqueta[] = "<body>";
const char finEtiqueta[] = "</body>";
size_t longitudInicioEtiqueta = strlen(inicioEtiqueta);
char *punteroInicio = strstr(contenido, inicioEtiqueta) + longitudInicioEtiqueta;
char *punteroFin = strstr(contenido, finEtiqueta);
if (punteroInicio == NULL || punteroFin == NULL)
{
printf("No se encontraron las etiquetas");
return;
}
char cuerpoHtml[TAMANIO_MAXIMO_CONTENIDO] = "";
char contenidoLimpio[TAMANIO_MAXIMO_CONTENIDO] = "";
size_t longitud = punteroFin - punteroInicio;
// Copiar el contenido del cuerpo a cuerpoHtml
strncpy(cuerpoHtml, punteroInicio, longitud);Hasta este momento ya tenemos el cuerpo, pero nos falta ignorar las etiquetas.
Ignorando etiquetas HTML y obteniendo solo texto usando C
Necesitamos declarar otra cadena, que será en donde estará el texto ya limpio sin etiquetas HTML. Más tarde podemos imprimir o guardar la cadena en un archivo de texto, mientras tanto el código que ignora las etiquetas es:
int i = 0;
const char simboloInicio = '<';
const char simboloFin = '>';
int ignorando = 0;
// Recorrer el cuerpo e ignorar etiquetas
for (i = 0; i < strlen(cuerpoHtml); i++)
{
char caracterActual = cuerpoHtml[i];
// Si encontramos una etiqueta abriendo, establecemos la bandera en true
if (caracterActual == simboloInicio)
{
ignorando = 1;
}
// Si encontramos el del final, establecemos la bandera en false
if (caracterActual == simboloFin)
{
ignorando = 0;
}
// Si no debo ignorar este carácter, y éste carácter no es >, entonces es un carácter válido
if (!ignorando && caracterActual != simboloFin)
{
// Aquí se puede hacer cualquier cosa con el char. Yo solo lo estoy concatenando
concatenarCharACadena(caracterActual, contenidoLimpio);
}
}Nos servimos de una bandera que nos dice si debemos tomar en cuenta el carácter actual o descartarlo. En caso de que el no debamos ignorar, concatenamos ese char a la cadena del resultado.
Al terminar, vamos a tener lo que necesitamos dentro de contenidoLimpio.
Poniendo todo junto
El código completo queda encerrado en una función que recibe el nombre del archivo que hay que parsear:
void extraerTexto(char *nombreArchivo)
{
FILE *archivo;
unsigned char bufer[TAMANIO_BUFER];
archivo = fopen(nombreArchivo, "r");
if (archivo == NULL)
{
printf("Error abriendo el archivo");
return;
}
// Leer archivo
char contenido[TAMANIO_MAXIMO_CONTENIDO] = "";
while (!feof(archivo))
{
fread(bufer, sizeof(char), sizeof(bufer), archivo);
// Almacenar contenido en el búfer
strcat(contenido, bufer);
}
// Extraer lo que hay entre <body> y </body>
const char inicioEtiqueta[] = "<body>";
const char finEtiqueta[] = "</body>";
size_t longitudInicioEtiqueta = strlen(inicioEtiqueta);
char *punteroInicio = strstr(contenido, inicioEtiqueta) + longitudInicioEtiqueta;
char *punteroFin = strstr(contenido, finEtiqueta);
if (punteroInicio == NULL || punteroFin == NULL)
{
printf("No se encontraron las etiquetas");
return;
}
char cuerpoHtml[TAMANIO_MAXIMO_CONTENIDO] = "";
char contenidoLimpio[TAMANIO_MAXIMO_CONTENIDO] = "";
size_t longitud = punteroFin - punteroInicio;
// Copiar el contenido del cuerpo a cuerpoHtml
strncpy(cuerpoHtml, punteroInicio, longitud);
int i = 0;
const char simboloInicio = '<';
const char simboloFin = '>';
int ignorando = 0;
// Recorrer el cuerpo e ignorar etiquetas
for (i = 0; i < strlen(cuerpoHtml); i++)
{
char caracterActual = cuerpoHtml[i];
// Si encontramos una etiqueta abriendo, establecemos la bandera en true
if (caracterActual == simboloInicio)
{
ignorando = 1;
}
// Si encontramos el del final, establecemos la bandera en false
if (caracterActual == simboloFin)
{
ignorando = 0;
}
// Si no debo ignorar este carácter, y éste carácter no es >, entonces es un carácter válido
if (!ignorando && caracterActual != simboloFin)
{
// Aquí se puede hacer cualquier cosa con el char. Yo solo lo estoy concatenando
concatenarCharACadena(caracterActual, contenidoLimpio);
}
}
// Aquí se puede hacer cualquier cosa con la cadena
printf("%s", contenidoLimpio);
}Para usarla podemos usar el siguiente código que ya lleva todo lo necesario:
/*
https://parzibyte.me/blog
*/#include <stdio.h>
#include <string.h>
#define TAMANIO_BUFER 1000
#define TAMANIO_MAXIMO_CONTENIDO 10000
void concatenarCharACadena(char c, char *cadena)
{
char cadenaTemporal[2];
cadenaTemporal[0] = c;
cadenaTemporal[1] = '\0';
strcat(cadena, cadenaTemporal);
}
void extraerTexto(char *nombreArchivo)
{
FILE *archivo;
unsigned char bufer[TAMANIO_BUFER];
archivo = fopen(nombreArchivo, "r");
if (archivo == NULL)
{
printf("Error abriendo el archivo");
return;
}
// Leer archivo
char contenido[TAMANIO_MAXIMO_CONTENIDO] = "";
while (!feof(archivo))
{
fread(bufer, sizeof(char), sizeof(bufer), archivo);
// Almacenar contenido en el búfer
strcat(contenido, (const char *)bufer);
}
// Extraer lo que hay entre <body> y </body>
const char inicioEtiqueta[] = "<body>";
const char finEtiqueta[] = "</body>";
size_t longitudInicioEtiqueta = strlen(inicioEtiqueta);
char *punteroInicio = strstr(contenido, inicioEtiqueta) + longitudInicioEtiqueta;
char *punteroFin = strstr(contenido, finEtiqueta);
if (punteroInicio == NULL || punteroFin == NULL)
{
printf("No se encontraron las etiquetas");
return;
}
char cuerpoHtml[TAMANIO_MAXIMO_CONTENIDO] = "";
char contenidoLimpio[TAMANIO_MAXIMO_CONTENIDO] = "";
size_t longitud = punteroFin - punteroInicio;
// Copiar el contenido del cuerpo a cuerpoHtml
strncpy(cuerpoHtml, punteroInicio, longitud);
int i = 0;
const char simboloInicio = '<';
const char simboloFin = '>';
int ignorando = 0;
// Recorrer el cuerpo e ignorar etiquetas
for (i = 0; i < strlen(cuerpoHtml); i++)
{
char caracterActual = cuerpoHtml[i];
// Si encontramos una etiqueta abriendo, establecemos la bandera en true
if (caracterActual == simboloInicio)
{
ignorando = 1;
}
// Si encontramos el del final, establecemos la bandera en false
if (caracterActual == simboloFin)
{
ignorando = 0;
}
// Si no debo ignorar este carácter, y éste carácter no es >, entonces es un carácter válido
if (!ignorando && caracterActual != simboloFin)
{
// Aquí se puede hacer cualquier cosa con el char. Yo solo lo estoy concatenando
concatenarCharACadena(caracterActual, contenidoLimpio);
}
}
// Aquí se puede hacer cualquier cosa con la cadena
printf("%s", contenidoLimpio);
}
int main(int argc, char const *argv[])
{
extraerTexto("index.html");
}
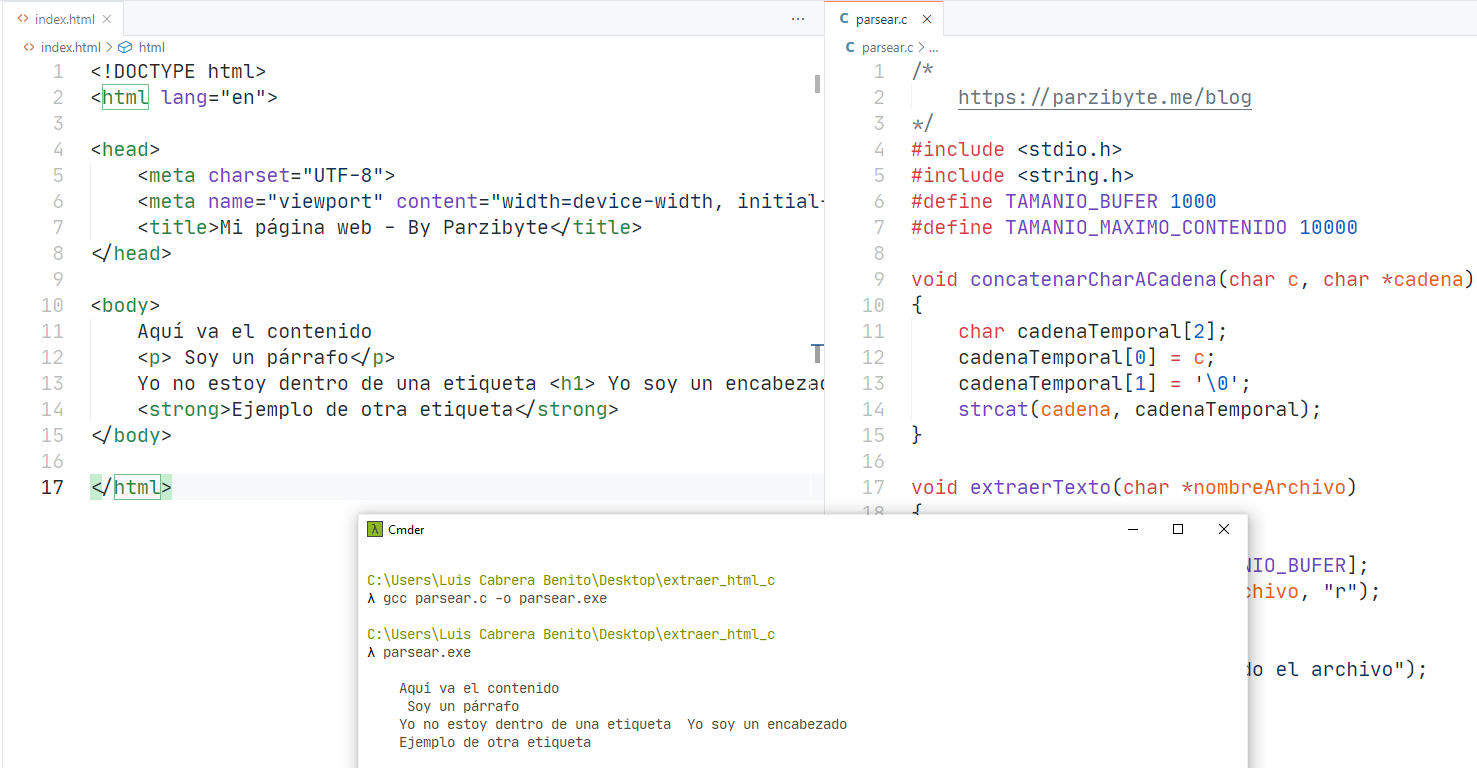
Yo lo he ejecutado y funciona de maravilla:
Si tú quieres puedes descargar el código y probarlo por ti mismo.
Para terminar te invito a leer más sobre programación en C en mi blog.

Entradas recientes
Cancelar trabajo de impresión con C++
En este post te quiero compartir un código de C++ para listar y cancelar trabajos…
Copiar bytes de Golang a JavaScript con WebAssembly
Gracias a WebAssembly podemos ejecutar código de otros lenguajes de programación desde el navegador web…
Imprimir PDF con Ghostscript en Windows de manera programada
Revisando y buscando maneras de imprimir un PDF desde la línea de comandos me encontré…
Hacer pruebas en impresora térmica Bluetooth Android
Esta semana estuve recreando la API del plugin para impresoras térmicas en Android (HTTP a…
Limpiar clave PEM
Hoy te enseñaré a extraer la cadena base64 de una clave PEM usando una función…
Foco con Telegram, apagador de 3 vías, relevador y ESP8266
Encender un foco con un Bot de Telegram es posible usando una tarjeta como la…