Extraer texto e imágenes de PDF con PHP


Imágenes y texto de PDF con PHP
Hoy vamos a ver cómo extraer el texto de un documento PDF, y también cómo extraer las imágenes que tiene el documento.
De esta manera podemos procesar un archivo PDF e indexarlo, ya que por defecto un archivo PDF no es legible como un txt u otro archivo simple.
Para leer un archivo PDF con PHP vamos a usar la librería PdfParser, la cual proporciona varias herramientas para extraer datos de un archivo PDF.
Instalar PdfParser
Si en tu proyecto ya usas Composer, simplemente instala PdfParser con:
composer require smalot/pdfparser
Si no usas Composer, mira aquí cómo comenzar a usarlo; o si ya tienes un proyecto de PHP y quieres adaptarlo mira este post.
Cuando esté instalado ahora requiere el autoload:
include "vendor/autoload.php";
Y con eso estamos listos para continuar.
Extraer texto de PDF con PdfParser
Para extraer el texto hay que crear una nueva instancia de Parser, obtener un documento con parseFile (pasándole la ruta del archivo PDF) y luego llamar al método getText(), así de fácil.
<?php
# Incluir autoload
include "vendor/autoload.php";
$parseador = new \Smalot\PdfParser\Parser();
$nombreDocumento = "6-imagenes.pdf";
$documento = $parseador->parseFile($nombreDocumento);
$texto = $documento->getText();
echo "<pre>";
echo $texto;
echo "</pre>";
En este caso el archivo PDF es uno que hice al exportar un documento de Word creado con PHP.
Leer páginas
Existe otra manera de leer el texto de un PDF y es ir página por página; si estamos indexando un documento esto ayudaría a saber a cuál página pertenece el texto extraído.
Para obtener las páginas se invoca al método getPages del documento creado con parseFile.
Después de eso, las páginas se pueden iterar en un foreach y en cada iteración llamar al método getText de la página.
<?php
# Incluir autoload
include "vendor/autoload.php";
$parseador = new \Smalot\PdfParser\Parser();
$nombreDocumento = "6-imagenes.pdf";
$documento = $parseador->parseFile($nombreDocumento);
$paginas = $documento->getPages();
foreach ($paginas as $indice => $pagina) {
printf("<h1>Página #%02d</h1>", $indice + 1);
$texto = $pagina->getText();
echo "<pre>";
echo $texto;
echo "</pre>";
}
Extraer imágenes
Esta librería también permite extraer las imágenes con el método getObjectsByType.
Cuando se obtienen las imágenes igualmente se pueden iterar en un foreach y para obtener el contenido de la imagen se invoca al método getContent de cada imagen.
El contenido es realmente el contenido de la imagen, que se puede guardar en el disco duro con file_put_contents o mostrar como el atributo src de una imagen codificándola en base64.
<?php
# Incluir autoload
include "vendor/autoload.php";
$parseador = new \Smalot\PdfParser\Parser();
$nombreDocumento = "6-imagenes.pdf";
$documento = $parseador->parseFile($nombreDocumento);
$imagenes = $documento->getObjectsByType('XObject', 'Image');
$contador = 0; # Un índice
foreach ($imagenes as $imagen) {
file_put_contents(sprintf("Imagen_%02d.jpg", $contador + 1), $imagen->getContent());
$contador++;
}
En el ejemplo se guardan las imágenes en el disco duro, más adelante veremos cómo mostrarlas en el HTML.
Extraer imágenes y texto
Combinando los ejemplos de arriba se puede extraer tanto el texto como las imágenes.
<?php
# Incluir autoload
include "vendor/autoload.php";
$parseador = new \Smalot\PdfParser\Parser();
$nombreDocumento = "6-imagenes.pdf";
$documento = $parseador->parseFile($nombreDocumento);
$paginas = $documento->getPages();
foreach ($paginas as $indice => $pagina) {
printf("<h1>Página #%02d</h1>", $indice + 1);
$texto = $pagina->getText();
echo "<pre>";
echo $texto;
echo "</pre>";
}
$imagenes = $documento->getObjectsByType('XObject', 'Image');
foreach ($imagenes as $imagen) {
printf("<h1>Una imagen</h1><img src=\"data:image/jpg;base64,%s\"/>", base64_encode($imagen->getContent()));
}
En el código estoy mostrando la imagen como un elemento img de HTML codificando con base64.
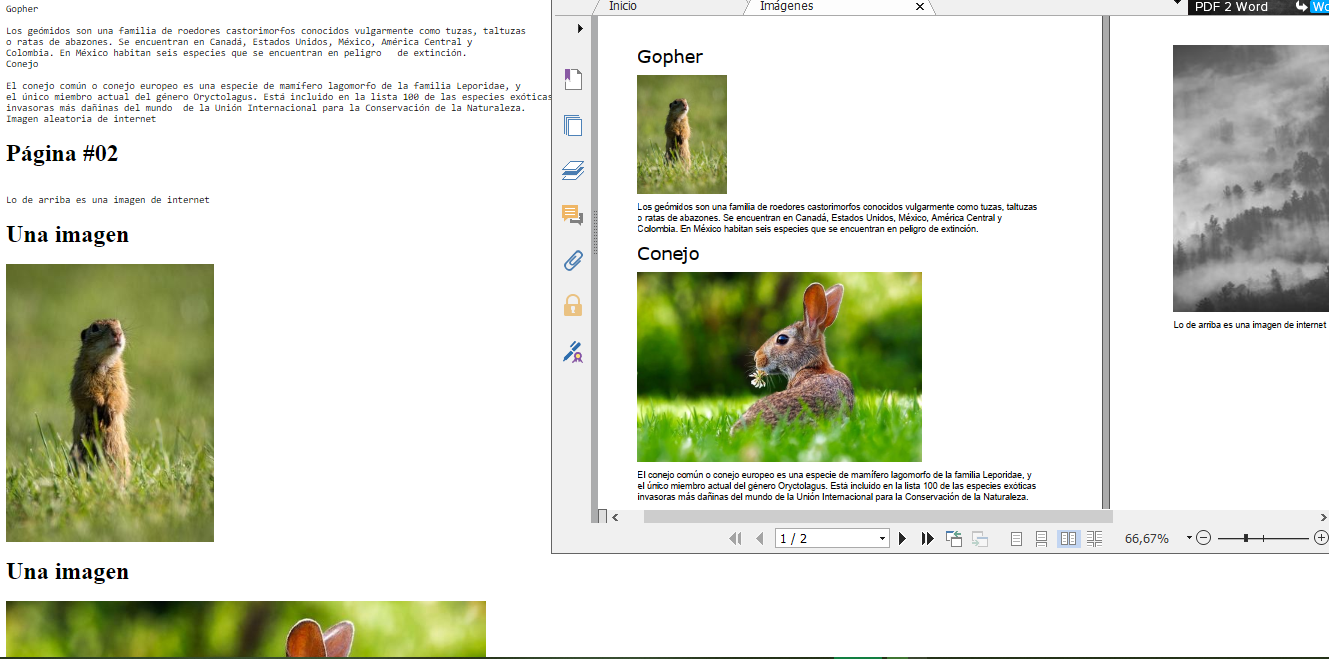
Múltiples archivos PDF
Con un arreglo se puede iterar a través de muchos archivos PDF. De hecho esta lista podría venir de leer el contenido de un directorio.
<?php
# Incluir autoload
include "vendor/autoload.php";
$parseador = new \Smalot\PdfParser\Parser();
$documentos = [
"2.1-textoEstilo.pdf",
"Ensayo.pdf",
"6-imagenes.pdf",
];
foreach ($documentos as $documento) {
printf("<h1>Documento %s</h1>", $documento);
$documento = $parseador->parseFile($documento);
$paginas = $documento->getPages();
foreach ($paginas as $indice => $pagina) {
printf("<h2>Página #%02d</h2>", $indice + 1);
$texto = $pagina->getText();
echo "<pre>";
echo $texto;
echo "</pre>";
}
}
Conclusión
De esta manera se pueden indexar múltiples documentos PDF y guardarlos en una base de datos.
Podrías guardar los datos en SQLite, MySQL o SQL Server. Igualmente el PDF podría venir de un formulario HTML que el usuario puede subir.
Por cierto, todo el código y los documentos PDF están en GitHub.

Entradas recientes
Cancelar trabajo de impresión con C++
En este post te quiero compartir un código de C++ para listar y cancelar trabajos…
Copiar bytes de Golang a JavaScript con WebAssembly
Gracias a WebAssembly podemos ejecutar código de otros lenguajes de programación desde el navegador web…
Imprimir PDF con Ghostscript en Windows de manera programada
Revisando y buscando maneras de imprimir un PDF desde la línea de comandos me encontré…
Hacer pruebas en impresora térmica Bluetooth Android
Esta semana estuve recreando la API del plugin para impresoras térmicas en Android (HTTP a…
Limpiar clave PEM
Hoy te enseñaré a extraer la cadena base64 de una clave PEM usando una función…
Foco con Telegram, apagador de 3 vías, relevador y ESP8266
Encender un foco con un Bot de Telegram es posible usando una tarjeta como la…
Ver comentarios
Hola tengo el siguiente error Undefined type 'Smalot\PdfParser\Parser'. al momento de implementar dicha librería, me pueden ayudar por favor.
Hola. Gracias por sus comentarios. Si tiene alguna consulta, solicitud de creación de un programa o solicitud de cambio de software estoy para servirle en https://parzibyte.me/#contacto
Saludos!
Se pueden extraer imagenes solo de la última página del pdf?Gracias y un saludo!
Yo creo que sí
Muy buenas
He estado probando el código para leer cada línea del pdf y me funciona de lujo.
¿Pero se podría separar cada campo de la línea con algún carácter como "|"?
Por ejemplo , en un línea me lee:
30805560 ESTA ES LA PRUEBA 1500 110,000 30 F
Y esos datos están metidos en diferentes cuadros de texto, pero en la misma línea.
¿Se podría mostrar como sigue?
30805560|ESTA ES LA PRUEBA 1500|110,000|30|F
Gracias.
Buenas tardes, lo único que se me ha ocurrido es modificar el fichero PDFObject.php, en la función getText, sustituyendo $text .= ' ';
por $text .= '|';
Si se os ocurre algo mejor, ya me decís.
Gracias.
Hola. Para consultas puede escribirme en https://parzibyte.me/#contacto
Hola. Gracias. Muy útil.
Necesito ayuda porque he intentado guardar en la base de datos, pero no he podido.
Mi código es el siguiente:
parseFile($nombreDocumento);
$paginas = $documento->getPages();
$guardar = "inicio";
foreach ($paginas as $indice => $pagina) {
printf("Página #%02d", $indice + 1);
$texto = $pagina->getText();
echo "";
echo $texto;
echo "";
$guardar = ("Página #%02d", $indice + 1);
$guardar .= "";
$guardar .= $texto;
$guardar .= "";
}
$guardar = "final";
$sql = "INSERT sac_datos_pdf SET fecha = '$fecha', nombre = '$nombreDocumento', contenido = '$guardar'";
$result = $mysqli->query($sql);
?>
Hola, buen día. Con gusto lo ayudo en: https://parzibyte.me/#contacto
Saludos :)
Hola
Estuve probando el código de ejemplo de GitHub, y muestra bien, pero al probar con el pdf que necesito trabajar, la pagina me genera un "ERR_CONNECTION_RESET" cuando uso getText(), pero cuando uso getDetails(), muestra la información correcta. Probé el pdf en la pagina de demostración de la librería y muestra de forma correcta el texto.
¿Que puede ser lo que está fallando?
saludos cordiales
Hola, este es el código que estoy probando:
parseFile($nombreDocumento);
$texto = $documento->getText();
echo "";
echo $texto;
echo "";
El pdf pesa 300k y es de 1 página, al parecer, es un problema con las tablas, ya que cree un pdf con un trozo del pdf a extraer que es una tabla 4 filas, y me pasa lo mismo....
Conoces alguna otra libreria para extraer textos de pdf??
Saludos
Puede que sea que la tabla es una imagen o algo así. No conozco otra librería pero igual podrías convertirlo a imagen y usar OCR para extraer el texto: https://parzibyte.me/blog/category/ocr/
Saludos
Hola qué tal. Si te genera un ERR_CONNECTION_RESET es un error HTTP, más allá de un error PHP; tal vez al obtener el texto estás sobrecargando al servidor o algo así y Apache se apaga; yo imagino eso; tal vez si pones un código de ejemplo alguien te pueda ayudar.
Saludos :)