Instalar Tesseract OCR + Idioma español en Ubuntu

Instalar modelos de tesseract ocr en español
Anteriormente en mi blog vimos cómo instalar Tesseract OCR en Windows 10 con los modelos para detectar el idioma español en el texto dentro de la imagen.
Tesseract OCR es un motor de reconocimiento óptico de caracteres, es decir, un motor que extrae el texto de una imagen, o digitaliza el contenido de una imagen, un escaneo, una foto o una captura de pantalla.
En este post vamos a ver cómo instalar Tesseract OCR en Ubuntu, además del idioma español o mejor dicho los modelos para trabajar con el idioma español.
Instalar Tesseract OCR en Ubuntu
Comienza ejecutando:
sudo apt-get update
Para actualizar los índices. Después instala tesseract OCR con:
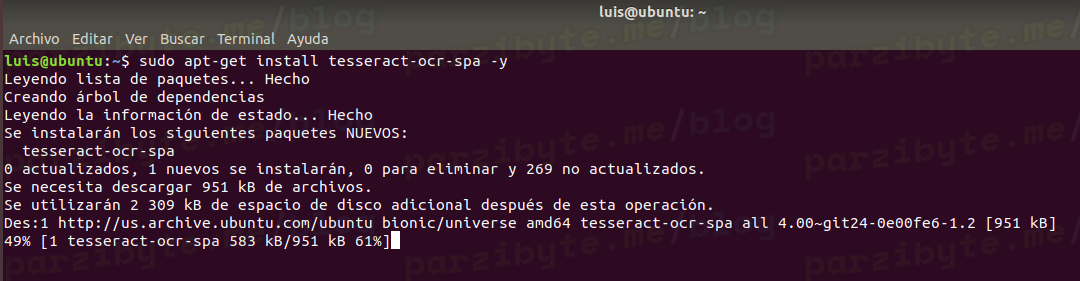
sudo apt-get install tesseract-ocr -y

Ahora instala los modelos del idioma español con:
sudo apt-get install tesseract-ocr-spa -y
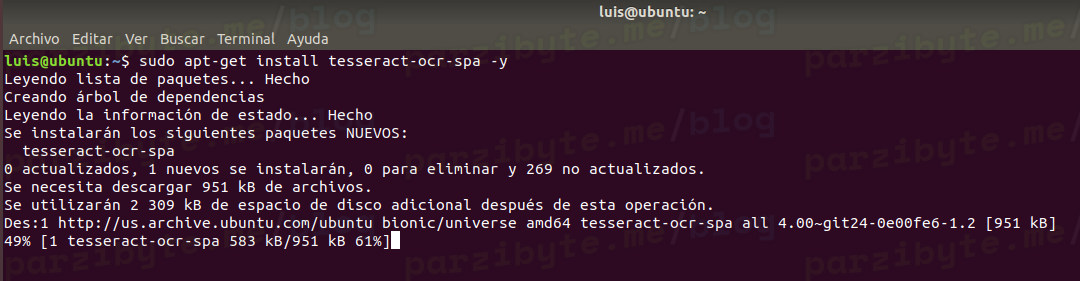
La parte spa es para indicar el idioma español. Y no, no es broma.
Finalmente lista los lenguajes instalados con:
tesseract --list-langs
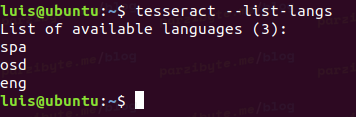
Eso probará 2 cosas: que hemos instalado tesseract sobre Ubuntu y que además tiene soporte para el idioma español.
¿Fácil, no? en los próximos posts veremos cómo usar Tesseract OCR para extraer el texto de imágenes.
Actualización: ya puedes ver cómo detectar el texto de una imagen en Ubuntu usando Tesseract.
Lo sé, la instalación es mil veces más fácil que en Windows.



Entradas recientes
Cancelar trabajo de impresión con C++
En este post te quiero compartir un código de C++ para listar y cancelar trabajos…
Copiar bytes de Golang a JavaScript con WebAssembly
Gracias a WebAssembly podemos ejecutar código de otros lenguajes de programación desde el navegador web…
Imprimir PDF con Ghostscript en Windows de manera programada
Revisando y buscando maneras de imprimir un PDF desde la línea de comandos me encontré…
Hacer pruebas en impresora térmica Bluetooth Android
Esta semana estuve recreando la API del plugin para impresoras térmicas en Android (HTTP a…
Limpiar clave PEM
Hoy te enseñaré a extraer la cadena base64 de una clave PEM usando una función…
Foco con Telegram, apagador de 3 vías, relevador y ESP8266
Encender un foco con un Bot de Telegram es posible usando una tarjeta como la…