Implementación del cifrado César en Python

Cifrado césar en Python
En un post anterior vimos cómo usar ord y chr en Python. Ahora veremos un caso práctico, el cual es aplicarlos para implementar el cifrado César en Python.
Seguramente por ahí habrá otras implementaciones, aquí presento la mía, espero que sea clara y explique cómo funciona el método de cifrado César en Python.
Lecturas recomendadas
- Lee cómo funciona chr y ord en Python
- Mira aquí cómo funciona el cifrado de César
- Aquí encuentras más información, en la Wikipedia
Al final obtendremos dos funciones que decodificarán y codificarán usando el cifrado de César en Python.
Algoritmo general y funciones
Vamos a usar isalpha para saber si un carácter es una letra del alfabeto. Si no lo es, entonces no rotamos nada y concatenamos el carácter así como es.
lower es para convertir una cadena a minúscula. De ahí usamos chr y ord para procesar cada letra.
isupper sirve para comprobar si la letra es mayúscula o minúscula, pues a partir de ello determinamos cuál alfabeto utilizar.
La rotación para codificar se hace sumando, y para decodificar restamos.
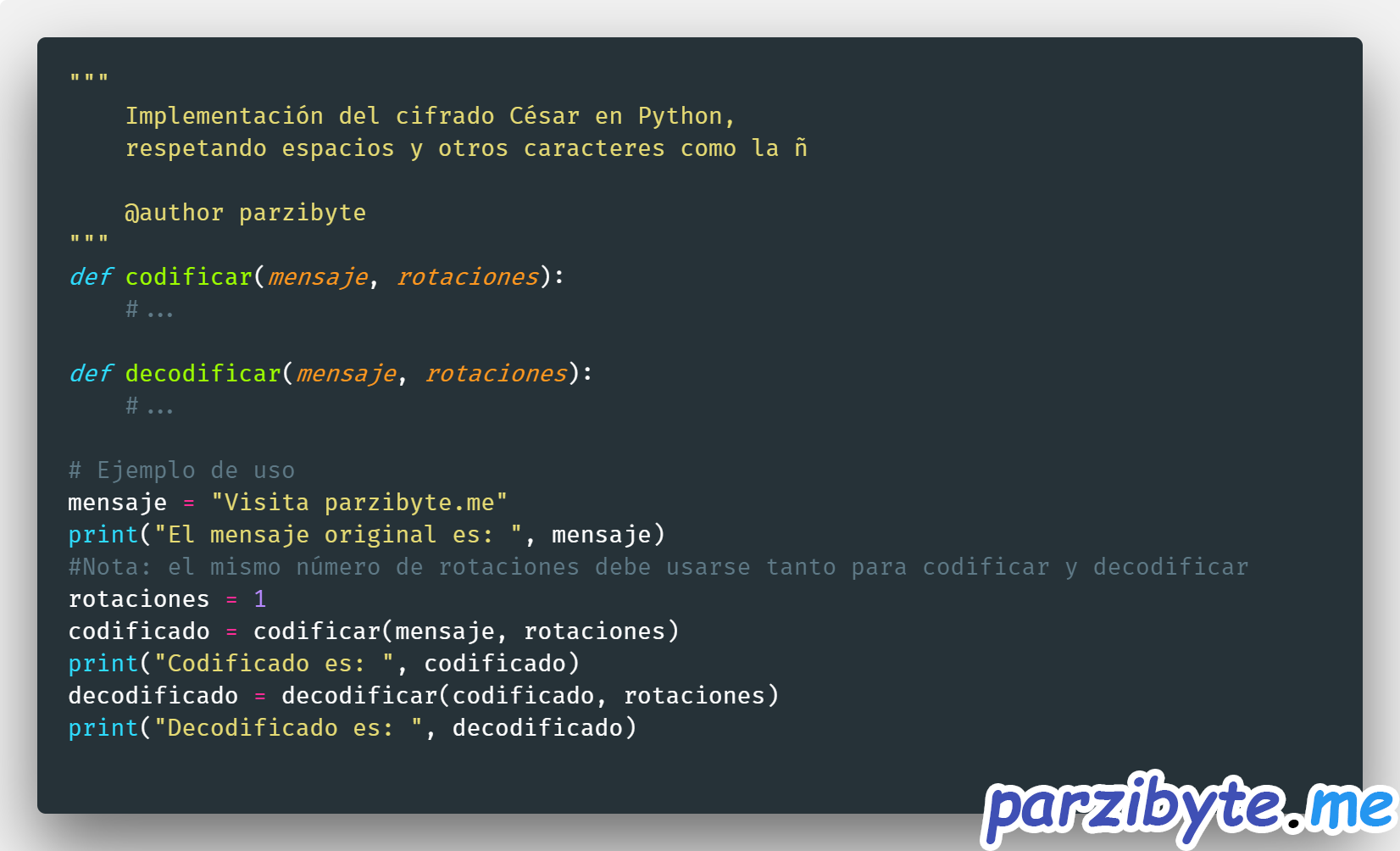
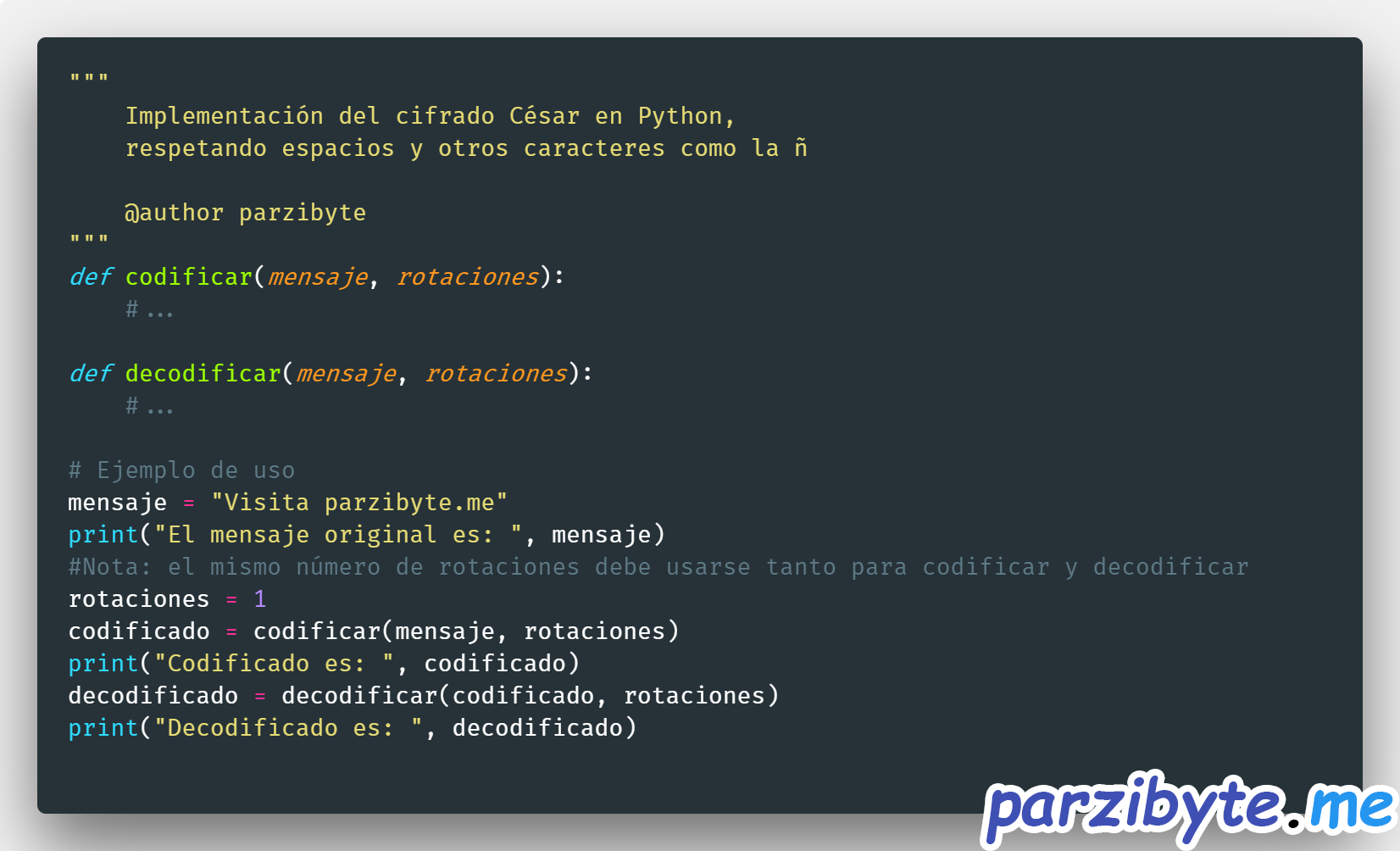
Cifrado César en Python
"""
Implementación del cifrado César en Python,
respetando espacios y otros caracteres como la ñ
@author parzibyte
"""
def codificar(mensaje, rotaciones):
#Nota: también se puede importar a string y usar ascii_letters y ascii_uppercase
alfabeto = "abcdefghijklmnopqrstuvwxyz"
alfabeto_mayusculas = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
longitud_alfabeto = len(alfabeto)
codificado = ""
for letra in mensaje:
if not letra.isalpha() or letra.lower() == 'ñ':
codificado += letra
continue
valor_letra = ord(letra)
# Suponemos que es minúscula, así que esto comienza en 97(a) y se usará el alfabeto en minúsculas
alfabeto_a_usar = alfabeto
limite = 97 # Pero si es mayúscula, comienza en 65(A) y se usa en mayúsculas
if letra.isupper():
limite = 65
alfabeto_a_usar = alfabeto_mayusculas
# Rotamos la letra
posicion = (valor_letra - limite + rotaciones) % longitud_alfabeto
# Convertimos el entero resultante a letra y lo concatenamos
codificado += alfabeto_a_usar[posicion]
return codificado
def decodificar(mensaje, rotaciones):
#Nota: también se puede importar a string y usar ascii_letters y ascii_uppercase
alfabeto = "abcdefghijklmnopqrstuvwxyz"
alfabeto_mayusculas = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
longitud_alfabeto = len(alfabeto)
decodificado = ""
for letra in mensaje:
if not letra.isalpha() or letra.lower() == 'ñ':
decodificado += letra
continue
valor_letra = ord(letra)
# Suponemos que es minúscula, así que esto comienza en 97(a) y se usará el alfabeto en minúsculas
alfabeto_a_usar = alfabeto
limite = 97 # Pero si es mayúscula, comienza en 65(A) y se usa en mayúsculas
if letra.isupper():
limite = 65
alfabeto_a_usar = alfabeto_mayusculas
# Rotamos la letra, ahora hacia la izquierda
posicion = (valor_letra - limite - rotaciones) % longitud_alfabeto
# Convertimos el entero resultante a letra y lo concatenamos
decodificado += alfabeto_a_usar[posicion]
return decodificado
# Ejemplo de uso
mensaje = "Visita parzibyte.me"
print("El mensaje original es: ", mensaje)
#Nota: el mismo número de rotaciones debe usarse tanto para codificar y decodificar
rotaciones = 1
codificado = codificar(mensaje, rotaciones)
print("Codificado es: ", codificado)
decodificado = decodificar(codificado, rotaciones)
print("Decodificado es: ", decodificado)
Ponemos dos funciones, decodificar y codificar. Ambas son casi lo mismo, excepto que una suma y otra resta. La forma de las mismas son:
codificar(mensaje, rotaciones)
decodificar(mensaje, rotaciones)
Reciben una cadena y el número de veces que se debe rotar.
Conclusiones
Espero que este algoritmo haya quedado claro. Tal vez no es el más óptimo, pero a mi modo de ver sí es el mejor explicado.
Sé que la letra ñ debería incluirse, porque hablamos el idioma español, pero iba a complicar las cosas un poco. Esto es debido a que en el Unicode sí está la Ñ, pero no se encuentra entre la n y la o, complicando las sumas y restas.
Claro que podría incluirse, pero quitaría un poco de legibilidad.

Entradas recientes
Resetear GOOJPRT PT-210 MTP-II (Impresora térmica)
El día de hoy vamos a ver cómo restablecer la impresora térmica GOOJPRT PT-210 a…
Proxy Android para impresora térmica ESC POS
Hoy voy a enseñarte cómo imprimir en una impresora térmica conectada por USB a una…
Android – Servidor web con servicio en segundo plano
En este post voy a enseñarte a programar un servidor web en Android asegurándonos de…
Cancelar trabajo de impresión con C++
En este post te quiero compartir un código de C++ para listar y cancelar trabajos…
Copiar bytes de Golang a JavaScript con WebAssembly
Gracias a WebAssembly podemos ejecutar código de otros lenguajes de programación desde el navegador web…
Imprimir PDF con Ghostscript en Windows de manera programada
Revisando y buscando maneras de imprimir un PDF desde la línea de comandos me encontré…
Ver comentarios
pero hay solo estas haciendo la codificación, si yo pongo un input y quiero decodificar, como se haria?