En este post te voy a enseñar a transmitir video y audio en tiempo real desde la tarjeta de desarrollo ESP32-CAM usando un micrófono ICS-43434 y la propia cámara OV2640 que tiene la ESP32-CAM.

Vamos a hacer la transmisión en tiempo real y de manera muy rápida usando UDP. El receptor puede ser cualquiera, pero en este caso lo haremos con Python.
Nota: antes de empezar esta transmisión de video y audio en tiempo real recomiendo que veas cómo enviar datos por UDP usando la ESP32-CAM
Disponibilidad de puertos I2S
Para leer del micrófono ICS 43434 necesitamos I2S. Según he investigado, la ESP32 ofrece 2 puertos I2S:
I2S_NUM_0I2S_NUM_1
Pero la propia cámara de la ESP32-CAM usa el puerto
I2S_NUM_0 y si lo intentamos usar va a haber reinicios
de Guru meditation o esp_camera_fb_get va a devolver
NULL.
Originalmente iba a hacer un transmisor receptor de audio, pero como no hay más puertos I2S lo dejé solo con micrófono y cámara.
Conexión de pines
En este caso solamente vamos a conectar el micrófono a la ESP32-CAM así que queda como se ve a continuación.
Es buen momento para dejar claro que yo he alimentado a la ESP32-CAM con un cargador viejo, conectando el del voltaje al 5V y el de GND a GND obviamente.
| ESP32-CAM | ICS-43434 |
|---|---|
| GND | GND |
| VCC | VDD |
| IO12 | SD |
| IO13 | WS |
| IO15 | SCK |
Calidad de transmisión de audio y video
En el código fuente que vas a encontrar a continuación vas a poder ajustar la calidad del video y la calidad del audio.
Recuerda: cuanta mejor calidad elijas, más lenta será la transmisión y la red se congestionará más.
Resolución y calidad de la cámara
Comencemos viendo cómo ajustar la resolución. Eso se hace en
la función inicializar_camara específicamente en:
config.frame_size = FRAMESIZE_SVGA;
config.jpeg_quality = 32; // calidad. Mejor calidad entre menor número. 0-63
Aquí frame_size puede tener alguna de las siguientes constantes,
siempre y cuando no supere los 2MP que ofrece la OV2640
typedef enum {
FRAMESIZE_96X96, // 96x96
FRAMESIZE_QQVGA, // 160x120
FRAMESIZE_QCIF, // 176x144
FRAMESIZE_HQVGA, // 240x176
FRAMESIZE_240X240, // 240x240
FRAMESIZE_QVGA, // 320x240
FRAMESIZE_CIF, // 400x296
FRAMESIZE_HVGA, // 480x320
FRAMESIZE_VGA, // 640x480
FRAMESIZE_SVGA, // 800x600
FRAMESIZE_XGA, // 1024x768
FRAMESIZE_HD, // 1280x720
FRAMESIZE_SXGA, // 1280x1024
FRAMESIZE_UXGA, // 1600x1200
// 3MP Sensors
FRAMESIZE_FHD, // 1920x1080
FRAMESIZE_P_HD, // 720x1280
FRAMESIZE_P_3MP, // 864x1536
FRAMESIZE_QXGA, // 2048x1536
// 5MP Sensors
FRAMESIZE_QHD, // 2560x1440
FRAMESIZE_WQXGA, // 2560x1600
FRAMESIZE_P_FHD, // 1080x1920
FRAMESIZE_QSXGA, // 2560x1920
FRAMESIZE_INVALID
} framesize_t;
Y jpeg_quality puede ir desde 0 hasta
63 en donde 0 es la mejor calidad y 63 la peor
Incluso así en la práctica no se puede obtener una
calidad de 0 con FRAMESIZE_UXGA
Algunas prueba de calidad
He hecho algunas pruebas y los resultados son:
- 0.25 fps con UXGA y calidad 2
- UXGA calidad 0 ni siquiera llegó un frame
- UXGA calidad 1 ni siquiera llegó un frame
- 0.1 fps con UXGA y calidad 3
- 4fps UXGA calidad 32
- 6fps HD calidad 32
- 12fps SVGA calidad 32
Frecuencia de muestreo del micrófono
La frecuencia más baja que he probado para poder capturar la voz humana con el micrófono es de 10Khz.
Para el caso del límite superior he grabado hasta 48Khz. Eso se ajusta en:
#define SAMPLE_RATE_MICROFONO 10000
Y en el receptor también:
TASA_MUESTREO_AUDIO = 10000
Otra cosa que influye es el tamaño del búfer del audio, pues:
- Si el búfer es pequeño va a haber más congestión de red pero la voz llegará más rápido y si un paquete se pierde no se habrá perdido mucha información
- Si el búfer es grande y se pierde, se habrá perdido una parte de la voz
Además, entre más alto sea el sample rate habrá una grabación de audio más pequeño en cada paquete, pues:
- Un sample rate de 10khz pesa menos, por lo tanto en un búfer del mismo tamaño la grabación tendrá una duración mayor
- Un sample rate de 48Khz pesa más, por lo tanto en un búfer del mismo tamaño la grabación tendrá una duración menor
Portando a otros lenguajes
En este caso he desarrollado el receptor con Python pero también puedes hacerlo con cualquier otro lenguaje de programación.
He probado recibir el audio con Android usando Kotlin y funciona bien, por lo que debe pasar lo mismo con el video, solo hay que desempacar los fotogramas.
Código fuente
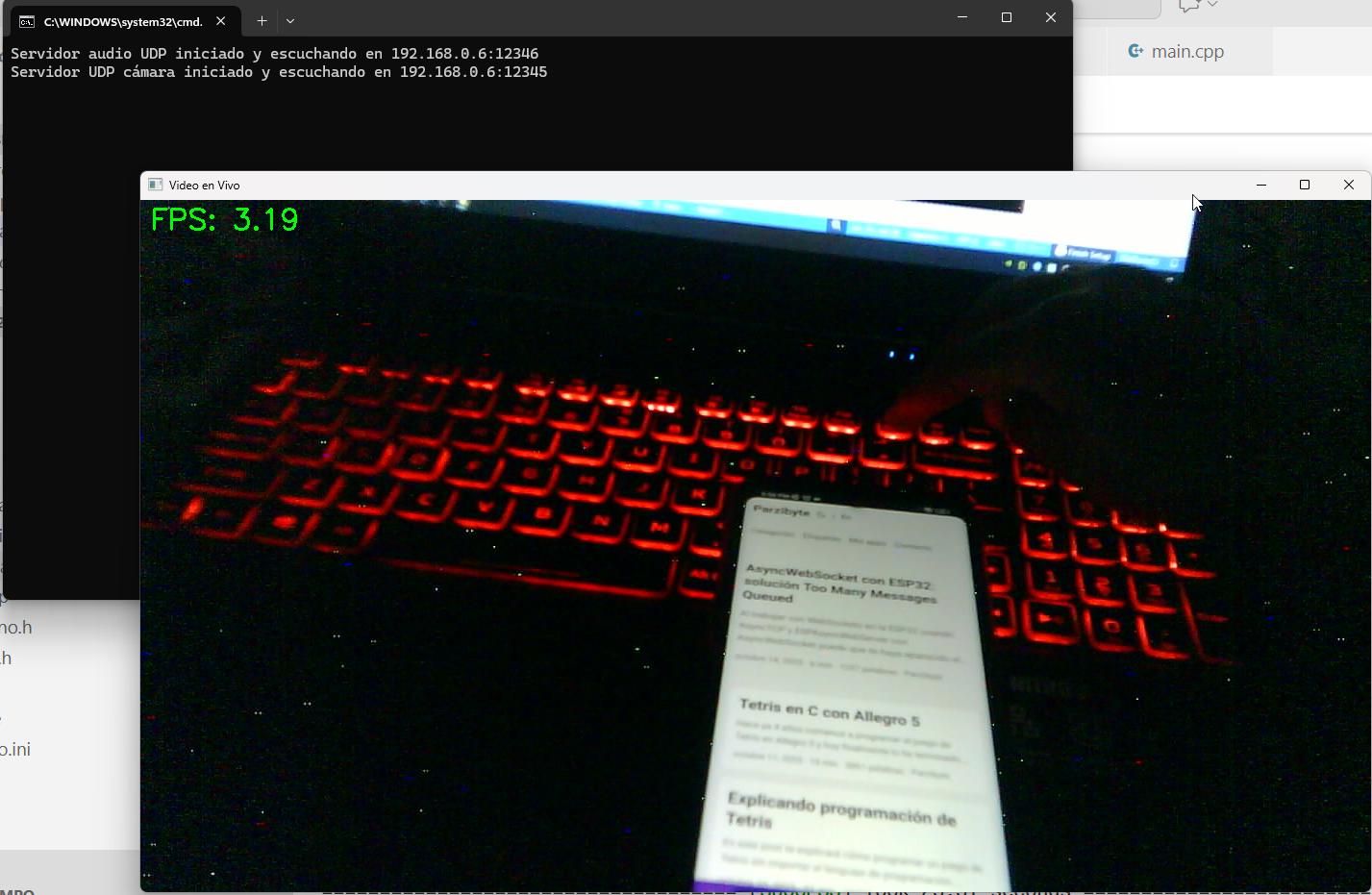
Dependencias de Python que debes instalar:
pip install opencv-python
pip install numpy
El platformio.ini de PlatformIO para los detalles de la tarjeta:
[env:esp32cam]
platform = espressif32
board = esp32cam
framework = arduino
monitor_speed=115200
monitor_rts = 0
monitor_dtr = 0
Ahora veamos todo lo que se encuentra dentro de src en el proyecto de PlatformIO:
Credenciales contenidas en credenciales.h:
#define NOMBRE_RED_WIFI ""
#define PASSWORD_RED_WIFI ""
Enviar cámara en enviar_camara.h:
#include "esp_camera.h"
#include "Arduino.h"
#define PUERTO_RECEPTOR_CAMARA 12345
#define IP_RECEPTOR_CAMARA "192.168.0.6"
#define PWDN_GPIO_NUM 32
#define RESET_GPIO_NUM -1
#define XCLK_GPIO_NUM 0
#define SIOD_GPIO_NUM 26
#define SIOC_GPIO_NUM 27
#define Y9_GPIO_NUM 35
#define Y8_GPIO_NUM 34
#define Y7_GPIO_NUM 39
#define Y6_GPIO_NUM 36
#define Y5_GPIO_NUM 21
#define Y4_GPIO_NUM 19
#define Y3_GPIO_NUM 18
#define Y2_GPIO_NUM 5
#define VSYNC_GPIO_NUM 25
#define HREF_GPIO_NUM 23
#define PCLK_GPIO_NUM 22
#define CHUNK_SIZE 1024
#pragma pack(push, 1) // Le dice al compilador: alinea a 1 byte (sin relleno)
typedef struct
{
uint16_t idImagen;
uint16_t indiceFragmento;
uint32_t tamanoTotal;
uint16_t totalFragmentos;
} EncabezadoFragmentoImagen;
#pragma pack(pop) // Restaura la configuración de alineación predeterminada
bool inicializar_camara()
{
camera_config_t config;
config.ledc_channel = LEDC_CHANNEL_0;
config.ledc_timer = LEDC_TIMER_0;
config.pin_d0 = Y2_GPIO_NUM;
config.pin_d1 = Y3_GPIO_NUM;
config.pin_d2 = Y4_GPIO_NUM;
config.pin_d3 = Y5_GPIO_NUM;
config.pin_d4 = Y6_GPIO_NUM;
config.pin_d5 = Y7_GPIO_NUM;
config.pin_d6 = Y8_GPIO_NUM;
config.pin_d7 = Y9_GPIO_NUM;
config.pin_xclk = XCLK_GPIO_NUM;
config.pin_pclk = PCLK_GPIO_NUM;
config.pin_vsync = VSYNC_GPIO_NUM;
config.pin_href = HREF_GPIO_NUM;
config.pin_sccb_sda = SIOD_GPIO_NUM;
config.pin_sccb_scl = SIOC_GPIO_NUM;
config.pin_pwdn = PWDN_GPIO_NUM;
config.pin_reset = RESET_GPIO_NUM;
config.xclk_freq_hz = 20000000;
config.pixel_format = PIXFORMAT_JPEG;
config.frame_size = FRAMESIZE_SVGA;
config.jpeg_quality = 32; // calidad. Mejor calidad entre menor número. 0-63
config.fb_count = 1;
return esp_camera_init(&config) == ESP_OK;
}
void taskEnviarCamara(void *pvParameters)
{
WiFiUDP udp;
uint16_t indiceImagen = 0;
EncabezadoFragmentoImagen encabezado;
while (true)
{
camera_fb_t *fb = esp_camera_fb_get();
if (fb)
{
// En cuántos lo vamos a dividir
uint16_t fragmentosNecesarios = (fb->len + CHUNK_SIZE - 1) / CHUNK_SIZE;
encabezado.idImagen = htons(indiceImagen);
encabezado.tamanoTotal = htonl(fb->len); // htons porque se va a dividir en 2 bytes seguramente
encabezado.totalFragmentos = htons(fragmentosNecesarios);
for (uint16_t indiceFragmento = 0; indiceFragmento < fragmentosNecesarios; indiceFragmento++)
{
encabezado.indiceFragmento = htons(indiceFragmento);
udp.beginPacket(IP_RECEPTOR_CAMARA, PUERTO_RECEPTOR_CAMARA);
udp.write((uint8_t *)&encabezado, sizeof(encabezado));
int longitud = CHUNK_SIZE;
int offset = indiceFragmento * CHUNK_SIZE;
if (longitud + offset > fb->len)
{
longitud = fb->len - offset;
}
udp.write(fb->buf + offset, longitud);
// Serial.printf("Escrito fragmento %d con longitud %d y offset %d\n", indiceFragmento, longitud, offset);
udp.endPacket();
}
esp_camera_fb_return(fb);
indiceImagen++;
}
else
{
Serial.printf("Error tomando foto. El frame buffer es null\n");
}
vTaskDelay(pdMS_TO_TICKS(10));
}
}
Enviar micrófono en microfono.h:
#include "driver/i2s.h"
#include "Arduino.h"
#define I2S_WS_MICROFONO 13 // LRCK
#define I2S_SD_MICROFONO 12 // DATA
#define I2S_SCK_MICROFONO 15 // BCL
#define SAMPLE_RATE_MICROFONO 10000
#define PIN_I2S_MICROFONO I2S_NUM_1
#define PUERTO_RECEPTOR_ICS 12346
#define IP_RECEPTOR_ICS "192.168.0.6"
#define TAMANO_PAQUETE_UDP_MICROFONO 512
void inicializar_i2s_microfono()
{
i2s_config_t i2s_config = {
.mode = (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_RX),
.sample_rate = SAMPLE_RATE_MICROFONO,
.bits_per_sample = I2S_BITS_PER_SAMPLE_16BIT,
.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT,
.communication_format = I2S_COMM_FORMAT_STAND_I2S,
.intr_alloc_flags = 0,
.dma_buf_count = 4,
.dma_buf_len = 256,
.use_apll = false};
;
i2s_pin_config_t pin_config = {
.bck_io_num = I2S_SCK_MICROFONO,
.ws_io_num = I2S_WS_MICROFONO,
.data_out_num = I2S_PIN_NO_CHANGE,
.data_in_num = I2S_SD_MICROFONO};
esp_err_t err = i2s_driver_install(PIN_I2S_MICROFONO, &i2s_config, 0, NULL);
if (err != ESP_OK)
{
Serial.printf("Error al instalar I2S mic: %d\n", err);
}
err = i2s_set_pin(PIN_I2S_MICROFONO, &pin_config);
if (err != ESP_OK)
{
Serial.printf("Error al configurar pines mic: %d\n", err);
}
Serial.println("Driver I2S instalado y configurado mic");
}
static uint8_t buffer[TAMANO_PAQUETE_UDP_MICROFONO];
void taskEnviarMicrofono(void *pvParameters)
{
WiFiUDP udp;
while (true)
{
// Comienza envío de audio
size_t bytesLeidosDeMicrofono = 0;
esp_err_t resultadoAlGrabarMicrofono = i2s_read(PIN_I2S_MICROFONO, buffer, TAMANO_PAQUETE_UDP_MICROFONO, &bytesLeidosDeMicrofono, portMAX_DELAY);
if (resultadoAlGrabarMicrofono != ESP_OK)
{
Serial.printf("Error leyendo mic: %d\n", resultadoAlGrabarMicrofono);
}
if (bytesLeidosDeMicrofono == TAMANO_PAQUETE_UDP_MICROFONO)
{
udp.beginPacket(IP_RECEPTOR_ICS, PUERTO_RECEPTOR_ICS);
udp.write(buffer, TAMANO_PAQUETE_UDP_MICROFONO);
udp.endPacket();
}
else
{
Serial.printf("bytesRead != maxLen\n");
}
// Si el delay es muy grande no te vas a escuchar
vTaskDelay(pdMS_TO_TICKS(10));
}
}
Main en main.cpp:
#include <Arduino.h>
#include <WiFi.h>
#include <WiFiUdp.h>
#include "udp.h"
#include "credenciales.h"
#include "enviar_camara.h"
#include "microfono.h"
void conectar_wifi()
{
Serial.println("Conectando wifi...");
WiFi.mode(WIFI_STA);
WiFi.disconnect(true, true);
delay(100);
wl_status_t resultado = WiFi.begin(NOMBRE_RED_WIFI, PASSWORD_RED_WIFI);
// Serial.printf("El resultado al conectar wifi es %d", resultado);
WiFi.setTxPower(WIFI_POWER_8_5dBm);
while (WiFi.status() != WL_CONNECTED)
{
delay(300);
Serial.print(".");
}
Serial.println(WiFi.localIP());
}
void setup()
{
Serial.begin(115200);
ledcSetup(0, 5000, 8);
ledcAttachPin(4, 0);
ledcWrite(0, 10);
delay(200);
ledcWrite(0, 1);
/*
Aquí pasaba algo muy curioso. Si yo invocaba
primero a inicializar_camara y luego a inicializar_i2s_microfono
la tasa de fotogramas de la cámara bajaba a 1.6fps, incluso si no enviaba
el audio. Y por otro lado, si yo invocaba primero al micrófono y luego
a la cámara entonces los fps subían a 12
*/
inicializar_i2s_microfono();
if (inicializar_camara())
{
Serial.printf("Camara inicializada");
}
else
{
Serial.printf("Error inicializando cam");
}
conectar_wifi();
// Prioridad. Low priority numbers denote low priority tasks.
xTaskCreate(taskEnviarCamara, "enviarCamara", 4000, NULL, 2, NULL);
xTaskCreate(taskEnviarMicrofono, "enviarMicrofono", 4000, NULL, 1, NULL);
}
void loop()
{
}
Receptor de audio y video usando hilos separados de Python:
import socket
import numpy as np
import pyaudio
import threading
import time
import cv2
import struct
# La ip de la computadora donde se ejecuta este script
IP_LOCAL = "192.168.0.6"
PUERTO_RECEPTOR_VIDEO = 12345
TAMAÑO_BUFER_VIDEO = 1500
PUERTO_AUDIO = 12346
TAMAÑO_BUFER_AUDIO = 512
TASA_MUESTREO_AUDIO = 10000
GANANCIA_VOLUMEN = 20
def receptor_audio():
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
try:
sock.bind((IP_LOCAL, PUERTO_AUDIO))
print(
f"Servidor audio UDP iniciado y escuchando en {IP_LOCAL}:{PUERTO_AUDIO}")
except Exception as e:
print(f"Error al asignar el socket: {e}")
exit()
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=TASA_MUESTREO_AUDIO,
output=True,
frames_per_buffer=TAMAÑO_BUFER_AUDIO // p.get_sample_size(pyaudio.paInt16))
while True:
try:
bytes_data, address = sock.recvfrom(
TAMAÑO_BUFER_AUDIO * 2) # Tal vez remover el *2?
if len(bytes_data) == TAMAÑO_BUFER_AUDIO:
audio_array = np.frombuffer(bytes_data, dtype=np.int16)
amplified_array = audio_array * GANANCIA_VOLUMEN
amplified_bytes = amplified_array.astype(np.int16).tobytes()
stream.write(amplified_bytes)
else:
print(
f"Paquete recibido con tamaño inesperado: {len(bytes_data)} bytes. Esperado: {TAMAÑO_BUFER_AUDIO}")
except KeyboardInterrupt:
print("\nCerrando servidor UDP...")
break
except Exception as e:
print(f"Error durante la recepción: {e}")
break
sock.close()
def receptor_video():
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
try:
sock.bind((IP_LOCAL, PUERTO_RECEPTOR_VIDEO))
print(
f"Servidor UDP cámara iniciado y escuchando en {IP_LOCAL}:{PUERTO_RECEPTOR_VIDEO}")
except Exception as e:
print(f"Error al asignar el socket: {e}")
exit()
ultimo_id_imagen = -1
ultima_longitud_imagen = 0
diccionario_imagen = {}
tiempo_anterior = time.time()
while True:
try:
bytes_data, address = sock.recvfrom(
TAMAÑO_BUFER_VIDEO)
id_imagen_host = struct.unpack('>H', bytes_data[:2])[0]
indice_fragmento = struct.unpack('>H', bytes_data[2:4])[0]
bytes_totales = struct.unpack('>L', bytes_data[4:8])[0]
total_fragmentos = struct.unpack('>H', bytes_data[8:10])[0]
fragmento_imagen = bytes_data[10:]
if id_imagen_host != ultimo_id_imagen:
# Ya es al menos la segunda vez que estamos recibiendo
ultima_longitud_imagen = bytes_totales
diccionario_imagen = {}
ultimo_id_imagen = id_imagen_host
diccionario_imagen[indice_fragmento] = fragmento_imagen
if len(diccionario_imagen) == total_fragmentos:
fragmentos_ordenados = [diccionario_imagen[i]
for i in sorted(diccionario_imagen.keys())]
imagen_final = b"".join(fragmentos_ordenados)
if len(imagen_final) == ultima_longitud_imagen:
imagen_array = np.frombuffer(imagen_final, dtype=np.uint8)
imagen_cv = cv2.imdecode(imagen_array, cv2.IMREAD_COLOR)
if imagen_cv is not None:
tiempo_actual = time.time()
diferencia = tiempo_actual - tiempo_anterior
if diferencia > 0:
fps = 1.0 / diferencia
else:
fps = 0
tiempo_anterior = tiempo_actual
fps_texto = f"FPS: {fps:.2f}"
cv2.putText(
imagen_cv,
fps_texto,
(10, 30),
cv2.FONT_HERSHEY_SIMPLEX,
1,
(0, 255, 0),
2
)
cv2.imshow("Video en Vivo", imagen_cv)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
print(
f"Mide {len(imagen_final)} pero debería medir {ultima_longitud_imagen}")
diccionario_imagen = {}
except KeyboardInterrupt:
print("\nCerrando servidor UDP...")
break
except Exception as e:
print(f"Error durante la recepción: {e}")
break
sock.close()
if __name__ == "__main__":
hilo_receptor_audio = threading.Thread(target=receptor_audio, daemon=True)
hilo_receptor_video = threading.Thread(target=receptor_video, daemon=True)
hilo_receptor_audio.start()
hilo_receptor_video.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
pass
Código anterior que solo estoy respaldando
Receptor de cámara Python
import socket
import time
import numpy as np
import struct
import cv2
# Debe coincidir con:
# udp.beginPacket(IP_RECEPTOR_CAMARA, PUERTO_RECEPTOR_CAMARA);
LOCAL_IP = "192.168.0.6"
# Debe coincidir con
# #define PUERTO_RECEPTOR_CAMARA 12345
LOCAL_PORT = 12345
BUFFER_SIZE = 1500
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
try:
sock.bind((LOCAL_IP, LOCAL_PORT))
print(f"Servidor UDP iniciado y escuchando en {LOCAL_IP}:{LOCAL_PORT}")
except Exception as e:
print(f"Error al asignar el socket: {e}")
exit()
ultimo_id_imagen = -1
ultima_longitud_imagen = 0
diccionario_imagen = {}
tiempo_anterior = time.time()
contador_frames = 0
while True:
try:
bytes_data, address = sock.recvfrom(
BUFFER_SIZE)
id_imagen_host = struct.unpack('>H', bytes_data[:2])[0]
indice_fragmento = struct.unpack('>H', bytes_data[2:4])[0]
bytes_totales = struct.unpack('>L', bytes_data[4:8])[0]
total_fragmentos = struct.unpack('>H', bytes_data[8:10])[0]
fragmento_imagen = bytes_data[10:]
# print(f"id {id_imagen_host} indice_Fragmento {indice_fragmento} bytes totales {bytes_totales} total_fragmentos {total_fragmentos}")
if id_imagen_host != ultimo_id_imagen:
# Ya es al menos la segunda vez que estamos recibiendo
# imagen.append(fragmento_imagen)
ultima_longitud_imagen = bytes_totales
diccionario_imagen = {}
ultimo_id_imagen = id_imagen_host
# print("Comenzada la recepción")
diccionario_imagen[indice_fragmento] = fragmento_imagen
if len(diccionario_imagen) == total_fragmentos:
fragmentos_ordenados = [diccionario_imagen[i]
for i in sorted(diccionario_imagen.keys())]
imagen_final = b"".join(fragmentos_ordenados)
if len(imagen_final) == ultima_longitud_imagen:
# print(f"{ultimo_id_imagen} Armado bien mide {len(imagen_final)}")
imagen_array = np.frombuffer(imagen_final, dtype=np.uint8)
imagen_cv = cv2.imdecode(imagen_array, cv2.IMREAD_COLOR)
if imagen_cv is not None:
tiempo_actual = time.time()
diferencia = tiempo_actual - tiempo_anterior
if diferencia > 0:
fps = 1.0 / diferencia
else:
fps = 0
tiempo_anterior = tiempo_actual
fps_texto = f"FPS: {fps:.2f}"
cv2.putText(
imagen_cv,
fps_texto,
(10, 30),
cv2.FONT_HERSHEY_SIMPLEX,
1,
(0, 255, 0),
2
)
cv2.imshow("Video en Vivo", imagen_cv)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
"""
nombre_archivo = f"imagen_id_{ultimo_id_imagen}.jpeg"
try:
with open(nombre_archivo, "wb") as f:
f.write(imagen_final)
print(
f"Imagen guardada exitosamente como: {nombre_archivo}")
except IOError as e:
print(f"Error al intentar guardar el archivo: {e}")
"""
else:
print(
f"Mide {len(imagen_final)} pero debería medir {ultima_longitud_imagen}")
diccionario_imagen = {}
except KeyboardInterrupt:
print("\nCerrando servidor UDP...")
break
except Exception as e:
print(f"Error durante la recepción: {e}")
break
sock.close()
Receptor de audio Python
import socket
import numpy as np
import pyaudio
import struct
# Debe coincidir con:
# udp.beginPacket("192.168.0.5", PUERTO_RECEPTOR_ICS);
LOCAL_IP = "192.168.0.6"
# Debe coincidir con
# #define PUERTO_RECEPTOR_ICS 12345
LOCAL_PORT = 12346
# Debe coincidir con
# #define UDP_PACKET_SIZE 2
BUFFER_SIZE = 512
# Debe coincidir con #define SAMPLE_RATE_MICROFONO 10000
SAMPLE_RATE = 10000
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
try:
sock.bind((LOCAL_IP, LOCAL_PORT))
print(f"Servidor UDP iniciado y escuchando en {LOCAL_IP}:{LOCAL_PORT}")
except Exception as e:
print(f"Error al asignar el socket: {e}")
exit()
p = pyaudio.PyAudio()
# Abrir el stream de audio para la reproducción (salida)
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=SAMPLE_RATE,
output=True,
frames_per_buffer=BUFFER_SIZE // p.get_sample_size(pyaudio.paInt16))
GAIN_FACTOR_PYTHON = 20
while True:
try:
bytes_data, address = sock.recvfrom(
BUFFER_SIZE * 2) # Tal vez remover el *2?
if len(bytes_data) == BUFFER_SIZE:
audio_array = np.frombuffer(bytes_data, dtype=np.int16)
# 2. Multiplicar cada muestra por el factor de ganancia (Aumentar volumen)
# NumPy maneja automáticamente el clipping al convertir de float a int16,
# pero es bueno ser explícito:
amplified_array = audio_array * GAIN_FACTOR_PYTHON
# 3. Volver a convertir el array amplificado a bytes
amplified_bytes = amplified_array.astype(np.int16).tobytes()
# 4. Escribir los bytes amplificados al stream
stream.write(amplified_bytes)
# Escribir los datos binarios directamente al stream de audio
# stream.write(bytes_data)
#print(f"Recibidos {len(bytes_data)} bytes de audio de {address}")
else:
print(
f"Paquete recibido con tamaño inesperado: {len(bytes_data)} bytes. Esperado: {BUFFER_SIZE}")
# print(f"Recibimos {len(bytes_data)} bytes de {address} y son {bytes_data}")
except KeyboardInterrupt:
print("\nCerrando servidor UDP...")
break
except Exception as e:
print(f"Error durante la recepción: {e}")
break
sock.close()