Te quiero compartir mi experiencia migrando mi antiguo blog de WordPress a GoHugo. No solo migré mi blog, también migré mis aplicaciones como Sublime POS 3, Sublime POS 4 y otras más, actualizando a un servidor más reciente.
Los cambios más significativos que hice son:
- Migré de WordPress a Hugo quitando dependencia de PHP y MySQL
- Migración de Apache a Nginx. Si bien no es una migración, ahora uso Nginx por defecto
- Cambio de sistema operativo de Ubuntu a Rocky Linux
Voy a enseñarte algunas cosas que aprendí así como el proceso que seguí para que sepas a lo que te puedes enfrentar al hacer esta migración.
¿Por qué migrar?
Dicen que si algo funciona no lo deberías tocar, y aunque todo en mi sitio funcionaba perfectamente el problema era que mi sistema operativo ya no se podía actualizar y lo tenía desde el 2019.
Debido a eso, ya tampoco podía actualizar PHP y por lo tanto WordPress me avisó que ya no podía seguir actualizando mis plugins.
Finalmente, la razón más obvia era que tener un sistema operativo sin actualizar es un gran riesgo de seguridad, y aunque realmente no guardo información confidencial en dicho servidor, no quería que alguien lo atacara
Migrando WordPress
El primer paso fue exportar WordPress como XML. La verdad no recuerdo cuál herramienta utilicé pero me parece que fue la del siguiente enlace:
https://github.com/SchumacherFM/wordpress-to-hugo-exporter
No pude usarlo como plugin; tuve que hacerlo con php hugo-export-cli.php abriendo
una sesión SSH para tener acceso a la terminal. Después lo copié con scp porque tampoco
pude descargarlo exitosamente desde el navegador web.
Después de eso me faltaba migrar los enlaces ya que además de que GoHugo cambia la estructura, no quería tener enlaces permanentes con URL absoluta; quería tener todo relativo por si en el futuro quiero volver a migrar.
Igualmente tenía que migrar las imágenes para que usaran mi shortcode de imagen optimizada para SEO. Todos mis intentos quedaron en el siguiente script de Python que leía el directorio que contenía los archivos Markdown, descargaba las imágenes, arreglaba los enlaces y los guardaba en una base de datos SQLite3:
"""
Necesitamos obtener el contenido
También escribir las rutas de redirección
Convertir el nombre a un slug o algo
También encontrar Youtube enlaces
También encontrar otros enlaces que no son imágenes, porque
una cosa es la imagen y otra cosa es un enlace
Poner todo en carpetas
Puro enlace y también los que están en un anchor. O sea los
<a href="aquí"> y los que están así nomás
Bueno entonces.
Extraer de enlaces:
Por ejemplo: [enviar un mensaje simple desde la NodeMCU ESP8266 a Telegram](https://parzibyte.me/blog/2024/05/28/esp8266-bot-telegram-enviar-mensaje/)
Expresión: (\[[\w ]+\])(\(https://parzibyte\.me/blog/\d{4}/\d{2}/\d{2}/[\w-]+/\))
Extraer pelones:
Por ejemplo: Te dejo todo en: https://parzibyte.me/blog/2024/05/28/esp8266-bot-telegram-enviar-mensaje/
Expresión: (?<!\()https://parzibyte\.me/blog/\d{4}/\d{2}/\d{2}/[\w-]+/(?!\))
[x] Extraer imágenes con caption (debe ejecutarse antes de las imágenes pelonas)
Por ejemplo: \[caption id="attachment\_343" align="aligncenter" width="1280"\][](https://parzibyte.me/blog/wp-content/uploads/2017/10/moorabbis-2782862_1280.jpg) Opacidad 100 %\[/caption\]
Expresión: (\\\[caption [\w\" \\=]*\\\](.*\((https://parzibyte\.me/blog/wp-content/uploads/\d{4}/\d{2}/[\w/-]+\.(?:png|webp|jpg|jpeg|gif))\)(.*))\\\[\/caption\\\])
Extraer imágenes:
Por ejemplo: [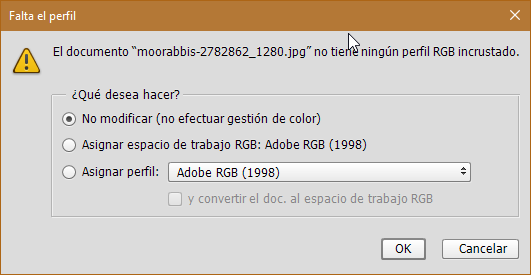](https://parzibyte.me/blog/wp-content/uploads/2017/10/No-modificar-imagen.png)
Expresión: (https://parzibyte\.me/blog/wp-content/uploads/\d{4}/\d{2}/[\w/-]*\.(?:png|webp|jpg|jpeg|gif))
Expresión corregida: \[!\[[\w ]*\]\((https://parzibyte\.me/blog/wp-content/uploads/\d{4}/\d{2}/[\w/-]*\.(?:png|webp|jpg|jpeg|gif))\)\]\(https://parzibyte\.me/blog/wp-content/uploads/\d{4}/\d{2}/[\w/-]*\.(?:png|webp|jpg|jpeg|gif)\)
Bueno entonces aquí vamos de nuevo. Definamos.
Primero leemos el archivo. Vamos a crear una carpeta con su slug, y dentro de esa carpeta colocaremos las imágenes leídas.
Entonces:
Leer contenido
Extraer nombre de la carpeta
Crear carpeta
Extraer las imágenes referenciadas
Descargar dichas imágenes en la carpeta previamente creada
Guardar el nombre de esas imágenes, ya que esas mismas serán las usadas para ponerlas en el nuevo post
Igualmente reemplazamos los enlaces
"""
from pathlib import Path
import os
import re
import requests
import sqlite3
from datetime import datetime
directorio_entradas = "entradas"
directorio_salidas = "salidas"
directorio_salidas_ingles = "salidas_en"
def convertir_url_imagen_a_ruta_relativa(url_imagen: str):
return url_imagen.split("/")[-1]
def descargar_imagen(url_imagen: str, carpeta_destino: str):
nombre_archivo = convertir_url_imagen_a_ruta_relativa(url_imagen)
ruta_completa_archivo = os.path.join(carpeta_destino, nombre_archivo)
if os.path.exists(ruta_completa_archivo):
print("Ya existe " + nombre_archivo)
return nombre_archivo
response = requests.get(url_imagen, stream=True)
response.raise_for_status()
with open(ruta_completa_archivo, 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
return nombre_archivo
def extraer_enlaces_coincidentes_raiz(contenido):
# Tal vez más preciso sería indicar que debe terminar con / pero no sé
regex_enlace = r"\n?.*https://parzibyte\.me/blog\n?.*"
enlaces_con_posibles_repetidos = re.findall(regex_enlace, contenido)
enlaces_sin_repetir = set(enlaces_con_posibles_repetidos)
return enlaces_sin_repetir
def extraer_enlaces_coincidentes(contenido):
# Tal vez más preciso sería indicar que debe terminar con / pero no sé
regex_enlace = r"(https:\/\/parzibyte.me\/blog\/[\w\/\-\.]+)"
enlaces_con_posibles_repetidos = re.findall(regex_enlace, contenido)
enlaces_sin_repetir = set(enlaces_con_posibles_repetidos)
return enlaces_sin_repetir
def descargar_imagenes_detectadas(carpeta_salida, contenido):
regex_imagen = r"(https://parzibyte\.me/blog/wp-content/uploads/\d{4}/\d{2}/[\w\.\-]*\.(?:png|webp|jpg|jpeg|gif))"
imagenes_con_posibles_repetidos = re.findall(regex_imagen, contenido)
imagenes_sin_repetir = set(imagenes_con_posibles_repetidos)
for imagen in imagenes_sin_repetir:
nombre_imagen_descargada = descargar_imagen(imagen, carpeta_salida)
def crear_carpeta(base, nombre):
ruta_carpeta = Path(base, nombre)
ruta_carpeta.mkdir(exist_ok=True)
return ruta_carpeta.absolute()
def obtener_nombre_carpeta(nombre_archivo_md):
regex_nombre = r"\d{4}-\d{2}-\d{2}-(.*)\.md"
match = re.search(regex_nombre, nombre_archivo_md)
if match:
return match.group(1)
return ""
def arreglar_captions(contenido_archivo):
regex_captions = r"(\\\[caption [\w\" \\=]*\\\](.*\((https://parzibyte\.me/blog/wp-content/uploads/\d{4}/\d{2}/[\w\.\-]+\.(?:png|webp|jpg|jpeg|gif))\)(.*))\\\[\/caption\\\])"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
ruta_imagen = match.group(3)
descripcion = match.group(4)
# Entonces será desde la última vez hasta el inicio
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "{{< optimized_image src=\"" + \
convertir_url_imagen_a_ruta_relativa(ruta_imagen) + "\""
cadena_final += " alt=\"" + descripcion.strip() + "\" loading=\"lazy\""
cadena_final += ">}}"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_imagenes_con_enlaces(contenido_archivo):
regex_imagenes = r"\[!\[([\w \-\#\+\/\,\:\.]*)\]\((https://parzibyte\.me/blog/wp-content/uploads/\d{4}/\d{2}/[\w\.\-]*\.(?:png|webp|jpg|jpeg|gif))\)\]\(https://parzibyte\.me/blog/wp-content/uploads/\d{4}/\d{2}/[\w\.\-]*\.(?:png|webp|jpg|jpeg|gif)\)"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_imagenes, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
ruta_imagen = match.group(2)
descripcion = match.group(1)
# Entonces será desde la última vez hasta el inicio
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "{{< optimized_image src=\"" + \
convertir_url_imagen_a_ruta_relativa(ruta_imagen) + "\""
cadena_final += " alt=\"" + descripcion.strip() + "\" loading=\"lazy\""
cadena_final += ">}}"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_categorias_dobles(contenido_archivo):
regex_captions = r"\[(https://parzibyte\.me/blog/category/([\w\-\. ]+)/?)\]\((https://parzibyte\.me/blog/category/([\w\-\. ]+)/?)\)"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
# Debe sacar algo como
# [Categoría]({{<tagref "javascript">}})
categoria = match.group(4)
# Entonces será desde la última vez hasta el inicio
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "[{{< tagref \""+categoria+"\" >}}]" + \
"({{< tagref \""+categoria+"\" >}})"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_categorias_ingles(contenido_archivo):
regex_captions = r"\[([\*\w \.\-\ \#\+\:\,\$\&\(\)\;\"]+)\]\((https://parzibyte\.me/blog/en/category/([\w\-\. ]+)/?)\)"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
descripcion_enlace = match.group(1)
# Debe sacar algo como
# [Categoría]({{<tagref "javascript">}})
categoria = match.group(3)
# Entonces será desde la última vez hasta el inicio
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "["+descripcion_enlace+"]" + \
"({{< tagref \""+categoria+"\" >}})"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_categorias(contenido_archivo):
regex_captions = r"\[([\*\w \.\-\ \#\+\:\,\$\(\)\;\"]+)\]\((https://parzibyte\.me/blog/category/([\w\-\. ]+)/?)\)"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
descripcion_enlace = match.group(1)
# Debe sacar algo como
# [Categoría]({{<tagref "javascript">}})
categoria = match.group(3)
# Entonces será desde la última vez hasta el inicio
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "["+descripcion_enlace+"]" + \
"({{< tagref \""+categoria+"\" >}})"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_contrataciones(contenido_archivo):
regex_captions = r"\[([\*\w \.\-\ ]+)\]\((https://parzibyte\.me/blog/contrataciones-ayuda/)\)"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
descripcion_enlace = match.group(1)
# Debe sacar algo como
# [Categoría]({{<tagref "javascript">}})
# Entonces será desde la última vez hasta el inicio
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "["+descripcion_enlace+"]" + \
"(https://parzibyte.me/#contacto)"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_tags(contenido_archivo):
regex_captions = r"\[([\*\w \.\-\ \#\+/\:\,]+)\]\((https://parzibyte\.me/blog/tag/([\w\-\. ]+)/?)\)"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
descripcion_enlace = match.group(1)
# Debe sacar algo como
# [Categoría]({{<tagref "javascript">}})
categoria = match.group(3)
# Entonces será desde la última vez hasta el inicio
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "["+descripcion_enlace+"]" + \
"({{< tagref \""+categoria+"\" >}})"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_internos_bold(contenido_archivo):
regex_captions = r"\[([\*\w \.\-\ \\\#\+/\:\,\$\?\¿\&\(\)\;\"]+)\]\((https://parzibyte\.me/blog/\d{4}/\d{2}/\d{2}/([\w\-\. ]+)/)\)"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
descripcion_enlace = match.group(1)
# Debe sacar algo como
# [Ya veo]({{< ref "/posts/2017-10-09-cambiar-opacidad-imagen-usando-photoshop.md" >}})
slug_sin_fecha = match.group(3)
# Entonces será desde la última vez hasta el inicio
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "["+descripcion_enlace+"]" + \
"({{< ref \"posts/"+slug_sin_fecha+"\" >}})"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_ingles(contenido_archivo):
regex_captions = r"\[([\w\ \-\.\,\:\$\\\/\*\&\(\)\;\"]+)\]\(https://parzibyte\.me/blog/en/\d{4}/\d{2}\/\d{2}/([\w\-]+)/\)"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
descripcion_enlace = match.group(1)
# Debe sacar algo como
slug_sin_fecha = match.group(2)
# Entonces será desde la última vez hasta el inicio
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "["+descripcion_enlace+"]" + \
"({{< ref path=\"posts/"+slug_sin_fecha+"\" lang=\"en\">}})"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_internos(contenido_archivo):
regex_captions = r"\[([\w \.\-\ \\\#\+/\:\,\$\?\¿\&\(\)\"\;]+)\](\(https://parzibyte\.me/blog/\d{4}/\d{2}/\d{2}/([\w\-\. ]+)/\))"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
descripcion_enlace = match.group(1)
# Debe sacar algo como
# [Ya veo]({{< ref "/posts/2017-10-09-cambiar-opacidad-imagen-usando-photoshop.md" >}})
slug_sin_fecha = match.group(3)
# Entonces será desde la última vez hasta el inicio
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "["+descripcion_enlace+"]" + \
"({{< ref \"posts/"+slug_sin_fecha+"\" >}})"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_dentro_2(contenido_archivo):
regex_enlaces_markdown = r"\[(https?://parzibyte\.me/blog/\d{4}/\d{2}/\d{2}/([\w\-\. ]+)/)\]\((https?://parzibyte\.me/blog/\d{4}/\d{2}/\d{2}/([\w\-\. ]+)/)\)"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_enlaces_markdown, contenido_archivo):
# Indices del inicio y fin de la COINCIDENCIA COMPLETA de la regex (el enlace Markdown)
indice_inicio_match = match.start()
indice_fin_match = match.end()
# Extraer el texto del enlace (que es la URL completa en tu caso)
# y el slug que necesitas para el ref de Hugo
# La URL completa del texto del enlace
texto_original_enlace = match.group(1)
slug_sin_fecha = match.group(2) # El slug sin la fecha
# Añadir la parte del contenido ANTES de la coincidencia actual
cadena_final += contenido_archivo[ultimo_fin:indice_inicio_match]
# Construir el nuevo enlace en formato Hugo
# Usamos el texto_original_enlace como texto visible del nuevo enlace
# y el slug_sin_fecha para la ruta de ref/relref
nuevo_enlace_hugo = f"[{texto_original_enlace}]({{< ref \"posts/{slug_sin_fecha}\" >}})"
# Añadir el nuevo enlace Hugo a la cadena final
cadena_final += nuevo_enlace_hugo
# Actualizar el último fin para la siguiente iteración
ultimo_fin = indice_fin_match
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
# Añadir el resto del contenido después de la última coincidencia
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_dentro(contenido_archivo):
regex_captions = r"\[(https://parzibyte\.me/blog/\d{4}/\d{2}/\d{2}/([\w\-\. ]+)/)\](\(https://parzibyte\.me/blog/\d{4}/\d{2}/\d{2}/([\w\-\. ]+)/\))"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
# Debe sacar algo como
# [Ya veo]({{< ref "/posts/2017-10-09-cambiar-opacidad-imagen-usando-photoshop.md" >}})
slug_sin_fecha = match.group(2)
# Entonces será desde la última vez hasta el inicio
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "[{{< ref \"posts/"+slug_sin_fecha+"\" >}}]" + \
"({{< ref \"posts/"+slug_sin_fecha+"\" >}})"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_comentarios_asterisco(contenido_archivo):
regex_captions = r"\* https://parzibyte\.me/blog\n \*/"
limpio = re.sub(regex_captions, '* {{< ref "/" >}}\n*/', contenido_archivo,flags=re.M)
limpio = re.sub(r"\* @see https://parzibyte\.me/blog",
'* {{< ref "/" >}}\n*/', limpio,flags=re.M)
limpio = re.sub(r"\"https://parzibyte\.me/blog\"",
'"{{<ref "/">}}"', limpio,flags=re.M)
limpio = re.sub(r"@see +https://parzibyte\.me/blog", '@see {{<ref "/">}}', limpio,flags=re.M)
limpio = re.sub(r"https://parzibyte\.me/blog$", '{{<ref "/">}}', limpio,flags=re.M)
limpio = re.sub(r"href=\"https://parzibyte\.me/blog\"", 'href=\"{{<ref "/">}}\"', limpio,)
return limpio
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
slug_sin_fecha = match.group(1)
# Debe sacar algo como
# [Ya veo]({{< ref "/posts/2017-10-09-cambiar-opacidad-imagen-usando-photoshop.md" >}})
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "[{{< ref path=\"posts/"+slug_sin_fecha+"\" lang=\"en\" >}}]" + \
"({{< ref \"posts/"+slug_sin_fecha+"\" lang=\"en\" >}})"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_pelones_ingles(contenido_archivo):
regex_captions = r"(?<!\()https://parzibyte\.me/blog/en/\d{4}/\d{2}/\d{2}/([\w-]+)/(?!\))"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
slug_sin_fecha = match.group(1)
# Debe sacar algo como
# [Ya veo]({{< ref "/posts/2017-10-09-cambiar-opacidad-imagen-usando-photoshop.md" >}})
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "[{{< ref path=\"posts/"+slug_sin_fecha+"\" lang=\"en\" >}}]" + \
"({{< ref \"posts/"+slug_sin_fecha+"\" lang=\"en\" >}})"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def arreglar_enlaces_pelones(contenido_archivo):
regex_captions = r"(?<!\()https://parzibyte\.me/blog/\d{4}/\d{2}/\d{2}/([\w-]+)/(?!\))"
cadena_final = ""
ultimo_fin = 0
hubo_coincidencias = False
for match in re.finditer(regex_captions, contenido_archivo):
indice_inicio = match.start()
indice_fin = match.end()
slug_sin_fecha = match.group(1)
# Debe sacar algo como
# [Ya veo]({{< ref "/posts/2017-10-09-cambiar-opacidad-imagen-usando-photoshop.md" >}})
cadena_final += contenido_archivo[ultimo_fin:indice_inicio]
# Luego ponemos lo que me interesa
cadena_final += "[{{< ref \"posts/"+slug_sin_fecha+"\" >}}]" + \
"({{< ref \"posts/"+slug_sin_fecha+"\" >}})"
# Luego ponemos desde el final
ultimo_fin = indice_fin
hubo_coincidencias = True
if not hubo_coincidencias:
return contenido_archivo
cadena_final += contenido_archivo[ultimo_fin:]
return cadena_final
def escribir_archivo_utf8(ruta_absoluta, contenido_cadena):
with open(ruta_absoluta, 'w', encoding='utf-8') as archivo:
archivo.write(contenido_cadena)
def es_entrada_ingles(nombre_archivo):
lista_entradas = [
"receipt-designer-thermal-printers-free-open-source",
"javascript-store-read-files-origin-private-file-system",
"javascript-download-file-with-fetch",
"sqlite3-vanilla-javascript-opfs-hello-world",
"python-thermal-printing-comprehensive-guide-printing-thermal-printers",
"image-printing-thermal-printer",
"print-diacritic-text-thermal-printer-esc-pos-commands",
"free-restaurant-software",
"passing-parameters-svelte-function",
"send-bytes-thermal-printer-c-sharp-esc-pos",
"fix-error-en-el-servidor-sql-no-rows-in-result-set-when-using-thermal-printer-plugin",
"silent-pdf-print-javascript-plugin",
"windows-print-pdf-cmd-pdftoprinter",
"start-program-windows-startup",
"pure-php-point-of-sale-system-with-mysql",
"laravel-pos-system-free-open-source",
"creating-api-rest-with-python-flask-sqlite3",
"tetris-game-javascript-open-source",
"api-rest-go-mysql",
"enable-cors-flask-app",
"connect-4-javascript-html",
"java-binary-text-translator",
"print-qr-codes-thermal-printer",
"php-mysql-tutorial-using-pdo",
"how-to-share-printer-windows",
"print-ticket-in-thermal-printer-directly-from-browser",
"a-plugin-for-printing-thermal-printers-from-browser",
"print-receipt-thermal-printer-javascript-css-html",
"custom-alert-dialog-android",
"how-to-redirect-spring-boot",
"change-express-generator-app-port",
"migrate-customers-table-mijoshop-opencart",
"reset-opencart-password-manually-database",
"install-opencart-3-windows-linux",
"install-node-js-npm-android-termux",
"install-apache-php-7-android-termux",
"install-mysql-mariadb-android-termux",
"configure-termux-android-linux",
"install-configure-python-3-pip-windows",
"switch-in-python",
"c-convert-string-lowercase-uppercase",
"python-check-if-item-value-exists-in-list-array",
"php-generate-cryptographically-secure-token",
]
return nombre_archivo in lista_entradas
def main():
bd = sqlite3.connect("posts_"+get_current_custom_datetime()+".sqlite3")
cursor = bd.cursor()
cursor.execute("""CREATE TABLE IF NOT EXISTS posts(
id INTEGER PRIMARY KEY AUTOINCREMENT,
nombre_archivo TEXT NOT NULL,
contenido_antes TEXT NOT NULL,
contenido_despues TEXT NOT NULL
)""")
cursor.execute("""CREATE TABLE IF NOT EXISTS enlaces_coincidentes(
id INTEGER PRIMARY KEY AUTOINCREMENT,
nombre_archivo TEXT NOT NULL,
enlace TEXT NOT NULL
)""")
archivos_md = os.listdir(directorio_entradas)
for archivo in archivos_md:
full_path = os.path.join(directorio_entradas, archivo)
if os.path.isfile(full_path) and full_path.endswith(".md"):
contenido_archivo = Path(full_path).read_text(encoding="utf-8")
contenido_archivo_original = contenido_archivo
# Creamos
ruta_absoluta_carpeta = None
if es_entrada_ingles(obtener_nombre_carpeta(archivo)):
ruta_absoluta_carpeta = crear_carpeta(
directorio_salidas_ingles, obtener_nombre_carpeta(archivo))
else:
ruta_absoluta_carpeta = crear_carpeta(
directorio_salidas, obtener_nombre_carpeta(archivo))
# descargar_imagenes_detectadas(ruta_absoluta_carpeta,contenido_archivo)
# Descomenta lo siguiente solo si no hay imágenes
# descargar_imagenes_detectadas( ruta_absoluta_carpeta, contenido_archivo)
contenido_archivo = arreglar_comentarios_asterisco( contenido_archivo)
contenido_archivo = arreglar_captions(contenido_archivo)
contenido_archivo = arreglar_imagenes_con_enlaces(
contenido_archivo)
contenido_archivo = arreglar_enlaces_internos_bold(
contenido_archivo)
contenido_archivo = arreglar_enlaces_internos(contenido_archivo)
contenido_archivo = arreglar_enlaces_ingles(contenido_archivo)
contenido_archivo = arreglar_enlaces_categorias(contenido_archivo)
contenido_archivo = arreglar_enlaces_categorias_ingles(
contenido_archivo)
contenido_archivo = arreglar_enlaces_categorias_dobles(
contenido_archivo)
contenido_archivo = arreglar_enlaces_tags(contenido_archivo)
contenido_archivo = arreglar_enlaces_contrataciones(
contenido_archivo)
contenido_archivo = arreglar_enlaces_dentro(contenido_archivo)
contenido_archivo = arreglar_enlaces_pelones(contenido_archivo)
contenido_archivo = arreglar_enlaces_pelones_ingles(
contenido_archivo)
contenido_archivo = arreglar_comentarios_asterisco( contenido_archivo)
# Reemplazar literales
contenido_archivo = contenido_archivo.replace("https://parzibyte.me/blog/contrataciones-ayuda/", "https://parzibyte.me/#contacto").replace(
"https://parzibyte.me/blog/contacto", "https://parzibyte.me/#contacto").replace("https://parzibyte.me/blog/software-creado-por-parzibyte/", '{{<ref "/pages/software-creado-por-parzibyte/">}}').replace("https://parzibyte.me/blog/sigueme/", '{{<ref "/pages/sigueme/">}}').replace("https://parzibyte.me/blog/pagos-venta-software/", '{{<ref "/pages/pagos-venta-software/">}}').replace("https://parzibyte.me/blog/conoce-sublime-pos/", '{{<ref "/pages/conoce-sublime-pos/">}}').replace("// https://parzibyte.me/blog\n", '// {{< ref "/" >}}\n').replace("Blog: https://parzibyte.me/blog", 'Blog: {{< ref "/" >}}').replace(" https://parzibyte.me/blog\n*/", ' {{< ref "/" >}}\n*/').replace(" * https://parzibyte.me/blog\n*/", '* {{< ref "/" >}}\n*/').replace('https://parzibyte.me/blog\n"""', '{{< ref "/" >}}\n"""').replace(' https://parzibyte.me/blog\n*/', '{{< ref "/" >}}\n*/').replace(' * https://parzibyte.me/blog\n*/', ' * {{< ref "/" >}}\n*/').replace('* Visita https://parzibyte.me/blog para más tutoriales sobre Java', '* Visita {{<ref "/">}} para más tutoriales sobre Java').replace('** https://parzibyte.me/blog **', '** {{<ref "/">}} **').replace('"https://parzibyte.me/blog\n"', '"{{<ref "/">}}\n"').replace("'https://parzibyte.me/blog'","'{{<ref \"/\">}}'").replace("Luis Cabrera Benito", "Parzibyte").replace("Luis Cabrera", "Parzibyte")
# contenido_archivo = arreglar_imagenes_con_enlaces_parte_2( contenido_archivo)
ruta_absoluta_archivo = os.path.join(
ruta_absoluta_carpeta, "index.md")
escribir_archivo_utf8(ruta_absoluta_archivo, contenido_archivo)
cursor.execute("""INSERT INTO posts(nombre_archivo, contenido_antes, contenido_despues)
VALUES (?, ? ,?)""", [archivo, contenido_archivo_original, contenido_archivo])
enlaces = extraer_enlaces_coincidentes(contenido_archivo)
for enlace in enlaces:
cursor.execute("""INSERT INTO enlaces_coincidentes(nombre_archivo, enlace) VALUES (?, ?)""", [
archivo, enlace])
enlaces = extraer_enlaces_coincidentes_raiz(contenido_archivo)
for enlace in enlaces:
cursor.execute("""INSERT INTO enlaces_coincidentes(nombre_archivo, enlace) VALUES (?, ?)""", [
archivo, enlace])
bd.commit()
# bd.commit()
def get_current_custom_datetime():
now = datetime.now()
return now.strftime("%Y-%m-%dT%H_%M_%S")
main()
"""
Ya todo funciona. Tal vez se podría quitar la parte que comprueba si hubo coincidencias, pues el error que
tuvimos en la noche (sobre que se cortaba el texto porque no añadíamos el resto del texto) era porque olvidamos
añadir el texto restante
De cualquier manera, ya funciona aparentemente. Solo falta revisar y probar. Se me ocurre mejorar:
1. Si la imagen ya existe, no la descargamos de nuevo. También podríamos descargar todas de una vez.
2. Poner una base de datos SQLite3 con el contenido anterior y el nuevo, así podemos hacer consultas para reemplazar o para ver enlaces
Y ya de ahí solo resta ejecutar el script con toooodos los archivos que son como 2500
"""
# Primero arreglamos los caption, no? es que no importa, porque eso solo es para el index. Así que
# lo del index lo vemos después, ya que ahorita solo importa identificar las imágenes y descargarlas
# Descargar imágenes en la carpeta
# Referenciar
# Poner index.md con el contenido ya limpio
# Solo quedan 226 enlaces malformados con la actualización que hice de que solo tome en cuenta /blog
# Solo quedan 211 enlaces malformados con la actualización que hice de que debe tomar en cuenta + y #
# Solo quedan 204 enlaces malformados con la actualización que hice sobre la diagonal final opcional
# Solo quedan 195 enlaces malformados. La barra / es válida como descripción de enlace
# Solo quedan 179 enlaces malformados. Las descripciones también pueden contener dos puntos (:)
# Solo quedan 136 enlaces malformados. Las descripciones también pueden contener comas
# Solo quedan 134 enlaces malformados. Hay enlaces de categorías cuya descripción es el mismo enlace
# Solo quedan 132 enlaces malformados. Las descripciones pueden contener $
# Solo quedan 95 enlaces malformados. La descripción de la imagen puede contener más caracteres
# Solo quedan 93 enlaces malformados. Los enlaces pueden contener ¿?
# Solo quedan 87 enlaces malformados. La descripción de las imágenes puede contener puntos (.)
# Solo quedan 85 enlaces malformados. Para contrataciones y contacto en la página los mandé a contacto de la raíz
# Solo quedan 73 enlaces malformados. Ya estoy enlazando a páginas, también estoy enlazando a posts en inglés
# Solo quedan 68 enlaces malformados. Los enlaces en inglés pueden tener negritas en su descripción
# Solo quedan 62 enlaces malformados. Había enlaces pelones en inglés
# Solo quedan 57 enlaces malformados. Migré categorías en inglés
# Solo quedan 55 enlaces malformados. El & también puede ser una descripción de un enlace
# Solo quedan 49 enlaces malformados. Las descripciones también pueden contener ( y )
# Solo quedan 46 enlaces malformados. Las descripciones también pueden contener " y ;Obviamente es código muy desordenado, pues solo hacía la migración, revisaba si había faltantes en la base de datos y volvía a repetir arreglando los errores.
Cuando los errores fueron pocos entonces lo arreglé manualmente.
Redireccionando
Los posts anteriores eran así:
https://parzibyte.me/blog/año/mes/día/slug-del-post/
Y con GoHugo quedaron así:
https://parzibyte.me/blog/slug-del-post/
Así que tuve que configurar Nginx con una expresión regular para hacer la redirección con el código HTTP 301. Quedó así:
location ~ "^/blog/[0-9]{4}/[0-9]{2}/[0-9]{2}/(.+)/?$" {
return 301 /blog/posts/$1;
}
location ~ "^/blog/en/[0-9]{4}/[0-9]{2}/[0-9]{2}/(.+)/?$" {
return 301 /blog/en/posts/$1;
}
Por cierto, debido a que uso las llaves {} debí encerrarlas en comillas dobles.
Migrando Sublime POS 3
Algunos usuarios rentan el sistema en la nube por lo que tuve que migrarlo y dejarlos sin SSL por un momento. Estos usuarios eran lo más importante, pues no podía dejarlos sin sistema por un largo período de tiempo.
Ya platiqué sobre cómo migré Sublime POS 3 con Nginx. Para las bases de datos utilicé SCP. Al tener SQLite3 solo necesitaba copiar los archivos asegurándome de que nadie los abriera al mismo tiempo.
Actualmente no tengo PHP instalado
No extraño PHP y aunque anteriormente lo necesitaba para demostraciones lo cierto es que dichas demostraciones no eran obligatorias.
Tal vez lo habilite más adelante para montar ciertos sistemas. Le tengo mucho aprecio a PHP aunque ya casi no lo utilizo desde que conozco Golang, pero fue uno de mis primeros lenguajes con el que hice varios proyectos.
Migrando Sublime POS 4, creador de tarjetas, creador de tickets y documentación del plugin
Los sistemas que menciono en el título como lo son Sublime POS 4, Creador de tarjetas y el Creador de tickets se ejecutan del lado del cliente y solo es necesario servir los archivos estáticos que conforman al sistema, así que podría usar cualquier servidor que pueda servir archivos estáticos.
La documentación del Plugin impresoras térmicas es igualmente un montón de archivos estáticos.
GoHugo va a generar cambios mínimos a los archivos
Estaba un poco preocupado porque GoHugo genera muchísimos archivos al
ejecutar hugo, pero lo que me gustó (y aunque suene obvio, yo no sabía) es
que sí, la primera vez sí va a generar muchos archivos, pero después, cuando se
me ocurra escribir un nuevo artículo solo va a generar los cambios mínimos que
contengan los nuevos artículos.
Las imágenes también seguirán manteniendo su mismo nombre siempre y cuando el archivo siga siendo el mismo así como las redimensiones.
En resumen estoy muy contento con GoHugo. Puedo editar todo en VSCode con el plugin de Vim y tener una vista previa.
La primera vez que ejecuté hugo preferí hacer un zip, enviarlo
con scp al servidor y extraerlo ahí. Lo que planeo hacer después es usar rsync para copiar solo los nuevos archivos, y si
me lo preguntas utilizo MSYS2 MSYS en Windows para tener acceso a ssh, rsync, claves SSH
Pensamiento final sobre GoHugo
Siento que la guerra de CMS va a seguir existiendo. Yo considero a GoHugo mejor, pero no porque sea GoHugo, sino porque toma archivos Markdown como base y de ahí genera páginas.
Ya hay varios gestores que hacen eso. Si pudiera regresar al inicio de todo cuando comencé a escribir en mi blog, lo habría preferido hacer en GoHugo. Es mejor tener un Markdown central y después usar cualquier generador de tu preferencia en lugar de tener todo como HTML en una base de datos.
No tengo problema con el hecho de que hay que subir los archivos estáticos generados contrario a WordPress en donde puedes editar casi en vivo.
Tener todo con Markdown también permite hacer migraciones más adelante. Si en el futuro vuelvo a cambiar de servidor porque el antiguo ya no soporta actualizaciones solo debo subir mi contenido generado al nuevo servidor sin preocuparme por bases de datos o URLs permanentes.
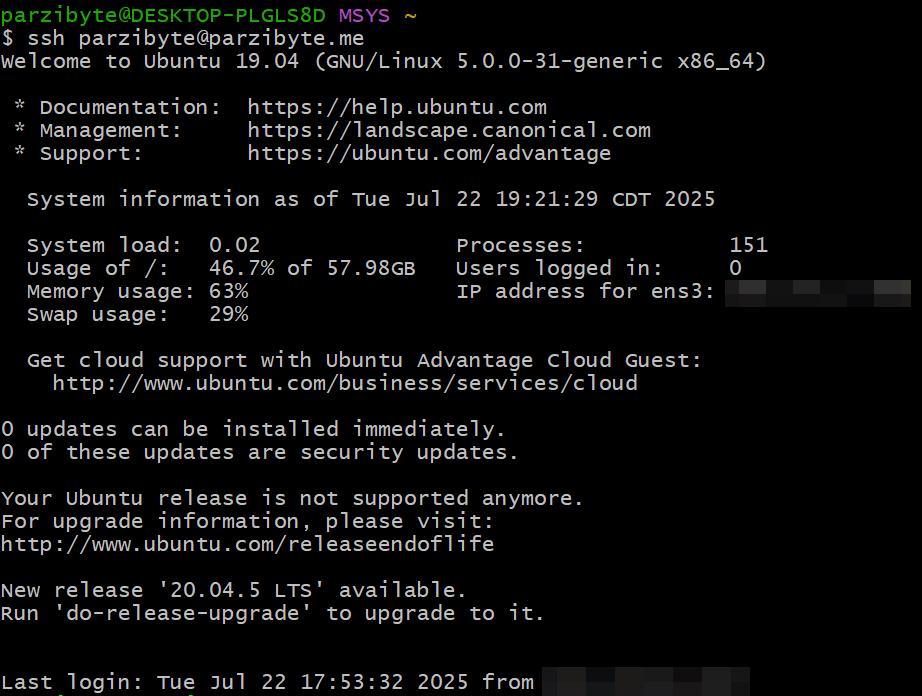
Una imagen para recordar
Finalmente aquí dejo una imagen de cómo me recibía mi antiguo servidor que sirvió tantos años: