Hablando de duplicidad, en alguna ocasión tuve que eliminar datos duplicados en MySQL y ya lo expliqué. Hoy explicaré cómo podemos eliminar duplicados en MongoDB, un gestor de base de datos que se compone de colecciones y que dentro de éstas aloja documentos.
Para este ejemplo utilizaré una base de datos de libros, en donde no puede repetirse el ISBN. Por favor nota que sólo es un base de datos de ejemplo, no esperes que los datos rean reales; se trata de ilustrar.
Insertaré esto:
db.libros.insert([
{
titulo:"El silencio de los corderos",
paginas:500,
isbn:"123" },
{
titulo:"¿Sueñan los androides con ovejas eléctricas?",
paginas:120,
isbn:"666" },
{
titulo:"El juego de Ender",
paginas:400,
isbn:"1234"// Notar que se repite el ISBN
},
{
titulo:"El principito",
paginas:400,
isbn:"1234"// ISBN repetido aquí
},
])
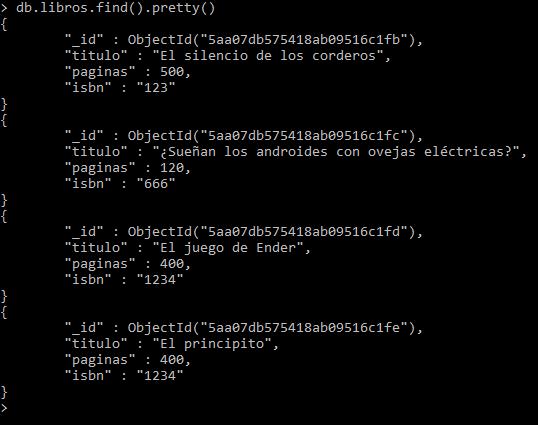
Consultaré los datos para ver si se han insertado:
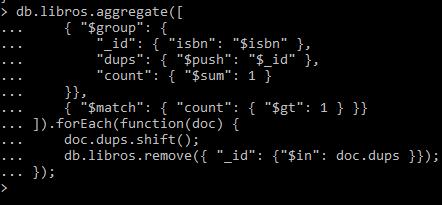
Hora de eliminar los repetidos. Nota: en este caso es un ejemplo algo raro, pero puede que en alguna ocasión nos falle sólo una palabra y tengamos que eliminar los duplicados.
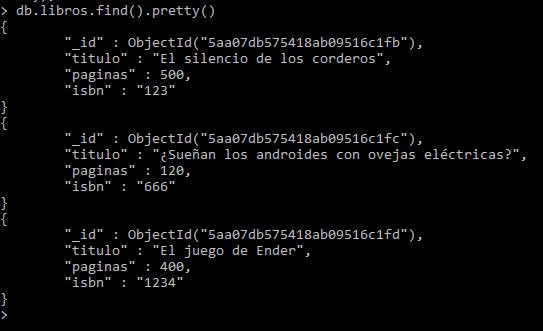
Y si vuelvo a consultar los datos existentes, veo esto:
¡Magia pura! ya no hay repetidos. Nos hemos quedado sólo con un dato. Esto funciona muy bien cuando tenemos documentos realmente repetidos, es decir, que todas sus claves sean idénticas; ya que de esta manera no importará cuál de ambos se elimine.
En este caso utilizamos al ISBN para eliminar, pero podemos utilizar cualquier clave.
Si el post ha sido de tu agrado te invito a que me sigas para saber cuando haya escrito un nuevo post, haya
actualizado algún sistema o publicado un nuevo software.
Facebook
| X
| Instagram
| Telegram |
También estoy a tus órdenes para cualquier contratación en mi página de contacto