Hoy vamos a ver cómo extraer el texto de un documento PDF, y también cómo extraer las imágenes que tiene el documento.
De esta manera podemos procesar un archivo PDF e indexarlo, ya que por defecto un archivo PDF no es legible como un txt u otro archivo simple.
Para leer un archivo PDF con PHP vamos a usar la librería PdfParser, la cual proporciona varias herramientas para extraer datos de un archivo PDF.
Instalar PdfParser
Si en tu proyecto ya usas Composer, simplemente instala PdfParser con:
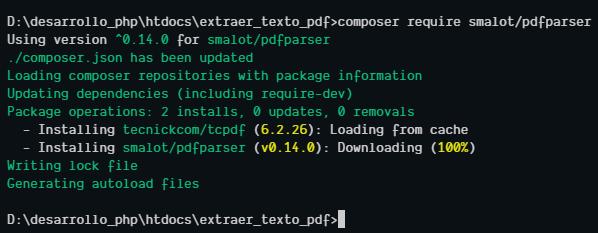
composer require smalot/pdfparser
Si no usas Composer, mira aquí cómo comenzar a usarlo; o si ya tienes un proyecto de PHP y quieres adaptarlo mira este post.
Cuando esté instalado ahora requiere el autoload:
include "vendor/autoload.php";
Y con eso estamos listos para continuar.
Extraer texto de PDF con PdfParser
Para extraer el texto hay que crear una nueva instancia de Parser, obtener un documento con parseFile (pasándole la ruta del archivo PDF) y luego llamar al método getText(), así de fácil.
<?php
# Incluir autoload
include "vendor/autoload.php";
$parseador = new \Smalot\PdfParser\Parser();
$nombreDocumento = "6-imagenes.pdf";
$documento = $parseador->parseFile($nombreDocumento);
$texto = $documento->getText();
echo "<pre>";
echo $texto;
echo "</pre>";
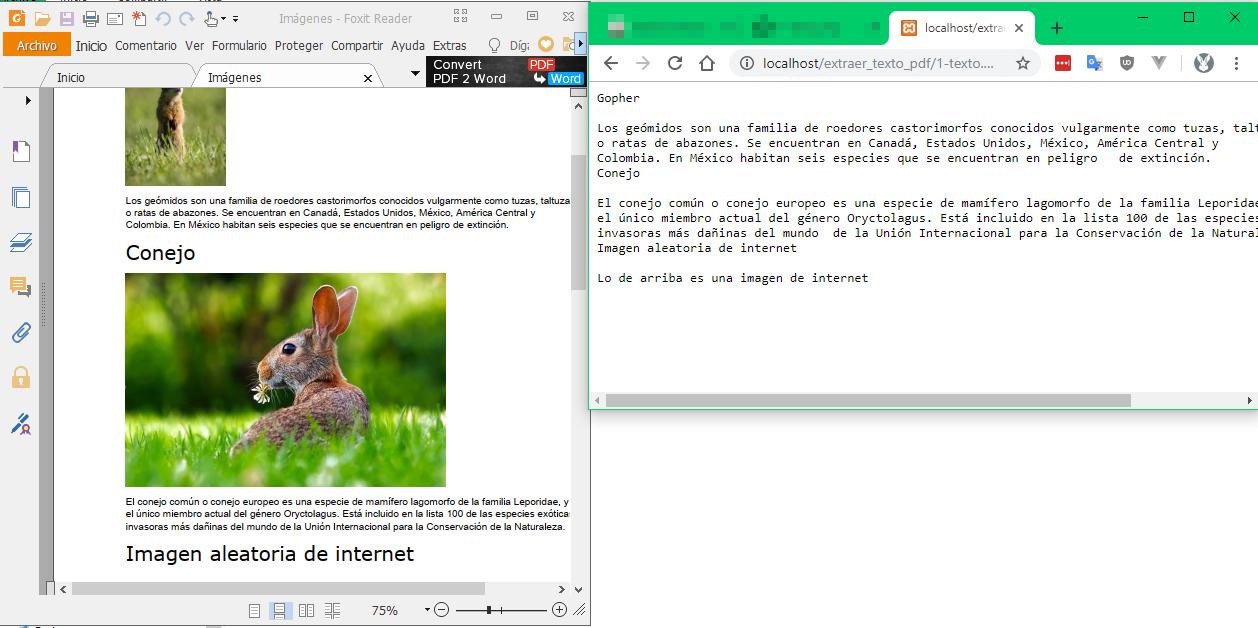
En este caso el archivo PDF es uno que hice al exportar un documento de Word creado con PHP.
Leer páginas
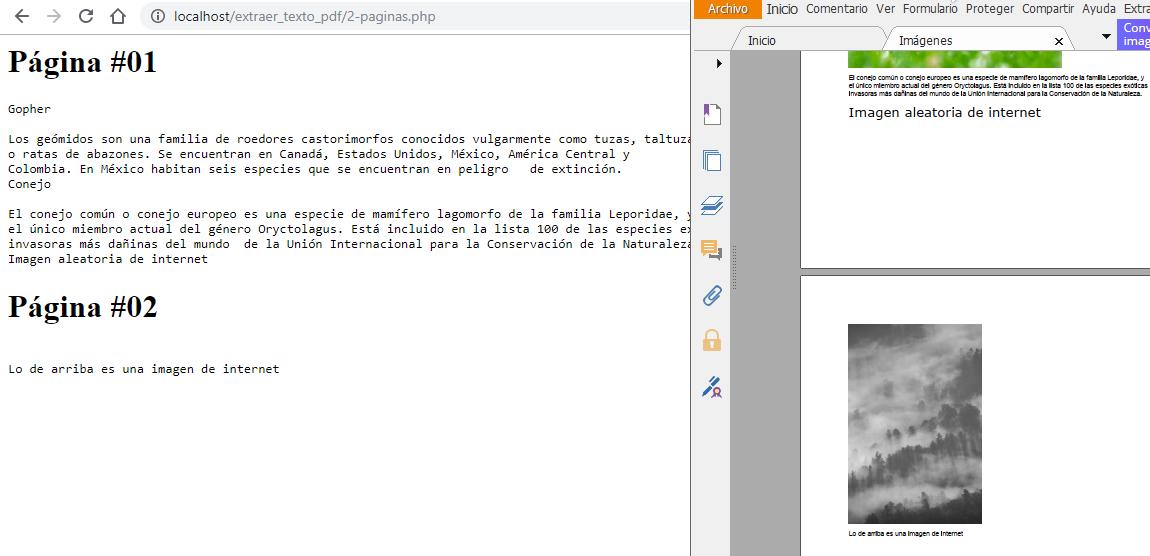
Existe otra manera de leer el texto de un PDF y es ir página por página; si estamos indexando un documento esto ayudaría a saber a cuál página pertenece el texto extraído.
Para obtener las páginas se invoca al método getPages del documento creado con parseFile.
Después de eso, las páginas se pueden iterar en un foreach y en cada iteración llamar al método getText de la página.
<?php
# Incluir autoload
include "vendor/autoload.php";
$parseador = new \Smalot\PdfParser\Parser();
$nombreDocumento = "6-imagenes.pdf";
$documento = $parseador->parseFile($nombreDocumento);
$paginas = $documento->getPages();
foreach ($paginas as $indice => $pagina) {
printf("<h1>Página #%02d</h1>", $indice + 1);
$texto = $pagina->getText();
echo "<pre>";
echo $texto;
echo "</pre>";
}
Extraer imágenes
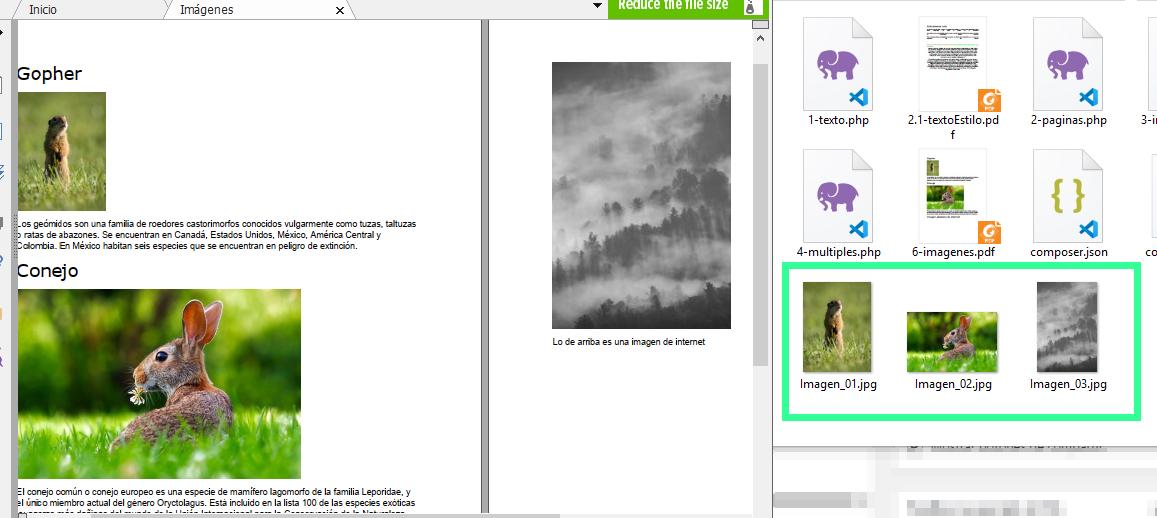
Esta librería también permite extraer las imágenes con el método getObjectsByType.
Cuando se obtienen las imágenes igualmente se pueden iterar en un foreach y para obtener el contenido de la imagen se invoca al método getContent de cada imagen.
El contenido es realmente el contenido de la imagen, que se puede guardar en el disco duro con file_put_contents o mostrar como el atributo src de una imagen codificándola en base64.
<?php
# Incluir autoload
include "vendor/autoload.php";
$parseador = new \Smalot\PdfParser\Parser();
$nombreDocumento = "6-imagenes.pdf";
$documento = $parseador->parseFile($nombreDocumento);
$imagenes = $documento->getObjectsByType('XObject', 'Image');
$contador = 0; # Un índice
foreach ($imagenes as $imagen) {
file_put_contents(sprintf("Imagen_%02d.jpg", $contador + 1), $imagen->getContent());
$contador++;
}
En el ejemplo se guardan las imágenes en el disco duro, más adelante veremos cómo mostrarlas en el HTML.
Extraer imágenes y texto
Combinando los ejemplos de arriba se puede extraer tanto el texto como las imágenes.
<?php
# Incluir autoload
include "vendor/autoload.php";
$parseador = new \Smalot\PdfParser\Parser();
$nombreDocumento = "6-imagenes.pdf";
$documento = $parseador->parseFile($nombreDocumento);
$paginas = $documento->getPages();
foreach ($paginas as $indice => $pagina) {
printf("<h1>Página #%02d</h1>", $indice + 1);
$texto = $pagina->getText();
echo "<pre>";
echo $texto;
echo "</pre>";
}
$imagenes = $documento->getObjectsByType('XObject', 'Image');
foreach ($imagenes as $imagen) {
printf("<h1>Una imagen</h1><img src=\"data:image/jpg;base64,%s\"/>", base64_encode($imagen->getContent()));
}
En el código estoy mostrando la imagen como un elemento img de HTML codificando con base64.
Múltiples archivos PDF
Con un arreglo se puede iterar a través de muchos archivos PDF. De hecho esta lista podría venir de leer el contenido de un directorio.
<?php
# Incluir autoload
include "vendor/autoload.php";
$parseador = new \Smalot\PdfParser\Parser();
$documentos = [
"2.1-textoEstilo.pdf",
"Ensayo.pdf",
"6-imagenes.pdf",
];
foreach ($documentos as $documento) {
printf("<h1>Documento %s</h1>", $documento);
$documento = $parseador->parseFile($documento);
$paginas = $documento->getPages();
foreach ($paginas as $indice => $pagina) {
printf("<h2>Página #%02d</h2>", $indice + 1);
$texto = $pagina->getText();
echo "<pre>";
echo $texto;
echo "</pre>";
}
}
Conclusión
De esta manera se pueden indexar múltiples documentos PDF y guardarlos en una base de datos.
Podrías guardar los datos en SQLite, MySQL o SQL Server. Igualmente el PDF podría venir de un formulario HTML que el usuario puede subir.
Por cierto, todo el código y los documentos PDF están en GitHub.