Tesseract OCR es un proyecto open source que trata sobre un motor de reconocimiento de texto en imágenes. Está disponible para Mac, Windows y Linux.
Hay buenas noticias para los hispanohablantes, pues Tesseract OCR tiene soporte para el español y la verdad es que me ha dejado maravillado con su precisión de reconocimiento.
En este post vamos a ver cómo instalar Tesseract OCR en Windows 10 para digitalizar imágenes, ya sea escaneos, fotos o capturas; cualquier imagen conteniendo texto será válida.
Resumiendo, vamos a ver:
- Cómo instalar Tesseract OCR en Windows
- Descargar el soporte para el idioma español
- Agregar Tesseract OCR a PATH de Windows
- Probar instalación de Tesseract
No te preocupes, este es un post inicial que sentará las bases para otros proyectos y demostraciones. Lo primero es instalar, descargar y configurar Tesseract, y lo segundo es usarlo.
Nota: si ya has instalado Tesseract mira cómo se usa aquí.
Descargar Tesseract OCR
Vamos a la wiki en GitHub y descargamos la versión para nuestra computadora, ya sea de 32 o 64 bits:
Cuando se descargue lo ejecutamos como administrador y damos todos los permisos necesarios.
Aceptamos licencias y hacemos click en Siguiente; dejamos todo por defecto:
Eso habrá instalado tesseract OCR en Windows. La ruta en donde se instaló por defecto es:
C:\Program Files\Tesseract-OCR
Guarda esa ruta, pues la vamos a ocupar más tarde.
Descargar idioma español
Por defecto, tesseract incluye únicamente el inglés. Para agregar más idiomas vamos al repositorio necesario, pero hay 2 maneras.
- La primera forma son los modelos rápidos
- La segunda, son los mejores modelos
Es decir, la primera es rápida pero no tan precisa, y la segunda es un poco más lenta pero precisa. Yo elegí la segunda y va de maravilla.
El modelo que es rápido se encuentra aquí, baja hasta encontrar el idioma que dice spa y descárgalo.
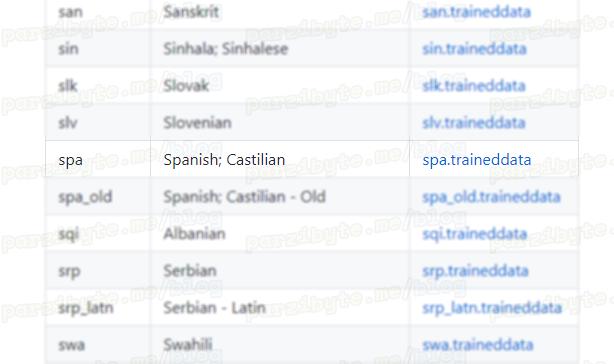
En caso de que quieras el mejor modelo (recomendado), igualmente en español, visita esta página. Baja hasta encontrar spa.traineddata:
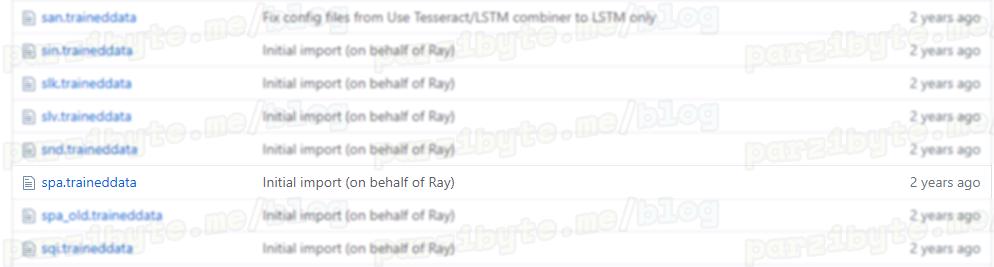
Después haz click en Download.
Instalar idioma español
Sin importar si seleccionaste la rápida o la mejor, tendrás un archivo llamado spa.traineddata.
Ese archivo vamos a colocarlo en la ruta de instalación de Tesseract OCR (si no lo modificaste, recuerda que es C:\Program Files\Tesseract-OCR) dentro de la carpeta tessdata.
Personalmente la pondré en:
C:\Program Files\Tesseract-OCR\tessdata
De manera que se ve así:
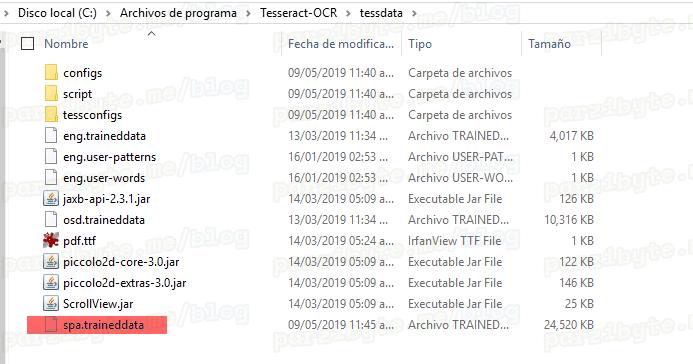
Agregar Tesseract a PATH
Para invocar el ejecutable tesseract desde cualquier lugar de la consola vamos a agregar la ruta de Tesseract (no la de tessdata, sino una carpeta arriba) a la Path de Windows.
Mira este post en donde se indica cómo se agrega la ruta a la PATH, al final debe lucir así:
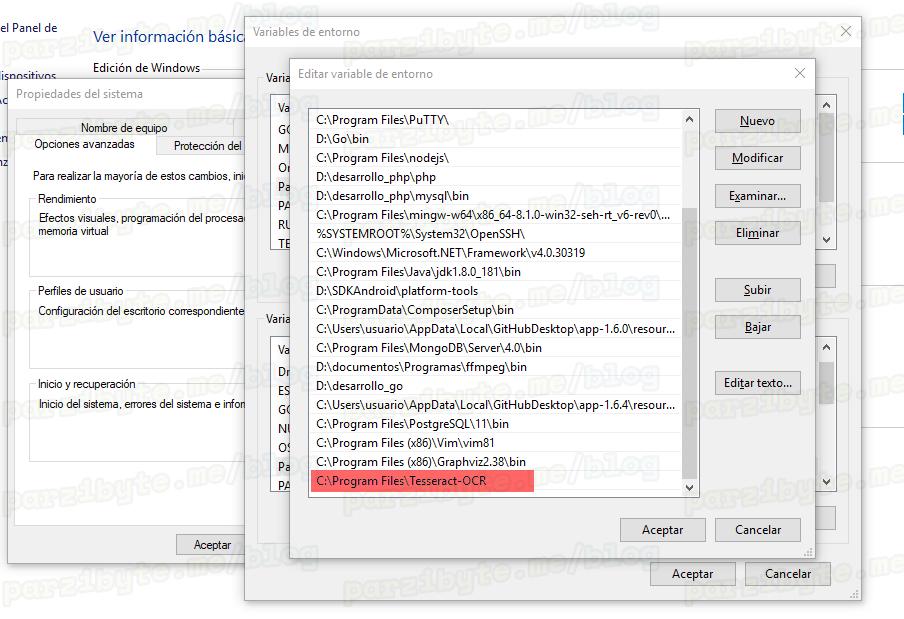
La ruta que hay que agregar es C:\Program Files\Tesseract-OCR en caso de que no hayas movido nada.
Probar instalación de Tesseract en Windows
Ahora, para probar todo lo configurado arriba, vamos a ejecutar el siguiente comando:
tesseract --list-langs
Con ello vamos a probar si agregamos tesseract a la PATH, y si instalamos el idioma español. La salida debe ser similar a la siguiente imagen:
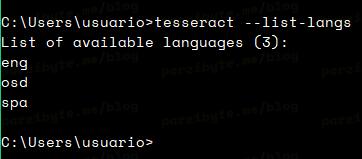
Ahí se puede observar que tenemos instalado el idioma spa, además de que el ejecutable tesseract funciona correctamente.
Conclusión
Paciencia, que más adelante traeré la segunda parte y más posts sobre OCR desde algunos lenguajes de programación.
Nota: ya está el post de cómo convertir imagen a texto en Windows usando OCR.
Te invito a suscribirte al blog en la parte de abajo.