Realizar conteo de ocurrencias de palabras en una oración con C
Ya estamos aquí con otro tutorial de C. Lo que haremos ahora será analizar una cadena o string, contar las palabras que tiene (ignorando puntos, espacios y signos) y luego agruparlas para indicar la frecuencia con la que se repiten.
Este ejercicio puede resolverse de varias maneras pero yo he decidido hacerlo a través de una pila en donde almacenaremos structs.
Aquí puedes ver un ejemplo de una pila de enteros, la modificaremos un poco para que funcione con structs.
¿Por qué una pila en lugar de un arreglo? muy fácil, porque la pila puede tener un tamaño infinito.
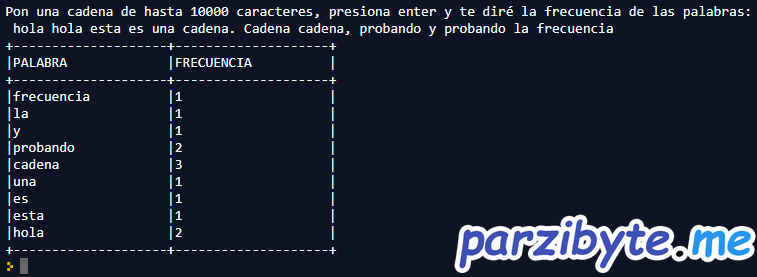
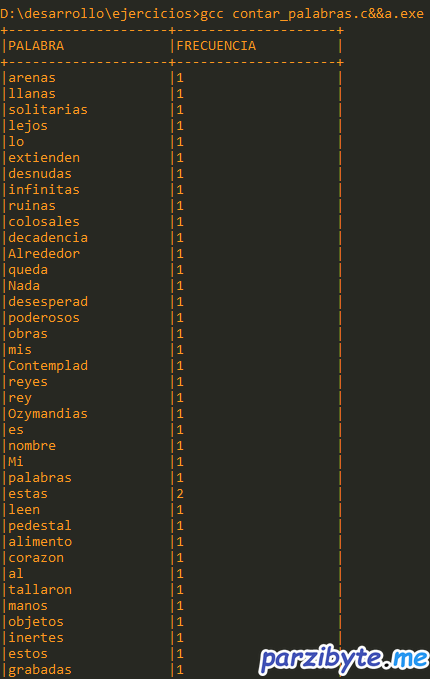
Al final generaremos una tabla como la que se ve en la imagen (aunque la frecuencia es 1 en la mayoría de veces, la función trabaja bien; el problema fue que la cadena de prueba no tenía muchas palabras repetidas):
El struct que tiene los detalles de palabras
Para no complicarnos, he creado un struct que tiene la palabra y su frecuencia. La palabra es una cadena, o más bien un arreglo de caracteres. Y la frecuencia un entero.
Como no podemos tener strings infinitas le hemos puesto un límite de 100. Se podría ampliar pero es un simple ejercicio, no algo de la vida real (aunque igualmente funciona de maravilla).
Más tarde crearemos un nodo que nos ayudará a formar nuestra pila. Ese nodo tendrá como dato un detalle de palabra:
También tendrá un apuntador a otro nodo; esto es por la naturaleza de la pila (si no entiendes, mira el post de las pilas que dejé al inicio).
Operaciones de la pila de structs
El ejercicio anterior fue para demostrar en todo su esplendor cómo trabajar con pilas en C. Sin embargo ahora aplicaremos esas pilas y quitaremos lo innecesario; por lo que quedan las operaciones agregar e imprimir.
El método de agregar pone un nuevo elemento, y el de imprimir recorre toda la pila para imprimir las palabras en una bonita tabla con frecuencias.
Adicionalmente (y este no es un método de las pilas) tenemos una función que busca una palabra… si ya existe, le aumenta la frecuencia.
Si no existe, entonces agrega un nuevo elemento a la pila y le pone la frecuencia en 1. Dicho método se llama agregarPalabra.
El prototipo de las funciones queda así:
Analizaremos una a una; sin caer en lo redundante.
Agregar a la pila
Es la operación push. Agrega un struct y ya:
Insertar palabra en la pila en caso de que no exista
Este sí es más complicado. Recorre toda la pila y va comparando sin ser sensible a mayúsculas y minúsculas con strcasecmp.
Si encuentra la palabra, le aumenta la frecuencia y termina la función.
Si el ciclo termina y llega al fondo de la pila, entonces llama al método agregar, le pasa un nuevo struct que tiene la palabra establecida en la búsqueda; y la frecuencia en 1.
Por cierto, podemos pensar que para asignar la palabra usaríamos:
detalleDePalabra.palabra = palabra
Pero no se puede asignar así; tenemos que copiar la cadena a un búfer, por eso usamos strcpy.
Imprimir resultados del conteo
El último método genera una tabla parecida a las que crea MySQL en la terminal.
Es generar encabezados, recorrer la pila y luego dibujar el pie:
Separar y contar palabras
Bueno, ya tenemos nuestra pila lista para trabajar. Lo que falta es leer toda una oración o texto e ir agregando cada palabra limpia.
Para ello usamos algo así como un split de la vieja escuela con strtok. Esta función divide o parte una cadena si encuentra delimitadores que le indicamos..
Recomiendo leer: dividir cadenas en C con strtok
Pero comencemos definiendo nuestra cadena que analizaremos, la cual es un poema de Ozymandias o algo así que sale en Breaking Bad:
Esa cadena también podría proporcionarla el usuario, no lo olvides.
De ahí el delimitador es un arreglo de caracteres. Cada que strtok encuentre uno de ellos, separará la cadena. De este modo ignoramos espacios, comas y esas cosas.
Ahora sí viene la magia, y justo aquí recorremos toda la cadena, tomamos cada palabra y trabajamos con ella:
La primera vez esta función devuelve el primer token que encuentre; o sea, la primer palabra que no sea un delimitador. Si no encontrara nada devolvería NULL, por eso la comprobación.
En caso de que sí regrese algo, entonces la agregamos. Y hacemos un ciclo while que seguirá hasta que ya no encontremos más palabras. En cada iteración agregamos la palabra.
Al terminar el ciclo, imprimimos los resultados.
Código completo
El código completo en donde ponemos todo junto lo dejo en un gist a continuación:
Si quieres, puedes probarlo aquí.
Bonus: frecuencia de palabras de una oración que el usuario introduzca
El poema que puse no nos da la forma de que juguemos con él si no somos programadores. Por ello vamos a modificar un poco la función de manera que el usuario introduzca la cadena y más tarde el programa imprima los valores.
Nada cambiará, únicamente la declaración de la cadena.
De ahí el algoritmo es el mismo, únicamente cambia la declaración como decía.
Puedes probarlo en el navegador.
En mi caso probé con una cadena sin sentido, pero que demostrará lo abordado en el post: