Introducción
Solución
Básicamente tenemos que agregar algunos índices a la tabla. Ya que, si recordamos, los índices son índices porque no se repiten (y porque ayudan a hacer las búsquedas más rápidas).
Entonces, si agregamos índices en los campos que no queremos que se repitan, se eliminarán de tal forma que, de todos los repetidos sólo quedará uno.
La consulta es:
ALTER IGNORE TABLE tu_tabla ADD UNIQUE INDEX(columna_1, columna_2);
En donde tu_tabla es el nombre de la tabla con datos repetidos. En este caso se supone que sólo son 2 columnas, pero podemos agregar muchas columnas.
Usamos IGNORE para que no nos dé ningún error, ya que nos intentará avisar que hay datos repetidos y que serán eliminados. Pero como nosotros ya sabemos que hay repetidos, ignoramos el error.
Después de hacerlo, podemos eliminar el índice usando:
ALTER TABLE tu_tabla DROP INDEX columna_1;
Aquí es importante mencionar que el nombre del índice es formado por el nombre de la primer columna. Por lo que si la primer columna fue “nombre” entonces el índice será “nombre” sin importar cuántas columnas hayas indexado.
Nota: está de más decir que debemos hacer un respaldo completo antes de hacer cualquier movimiento. Nunca se sabe si algo puede salir mal.
Ejemplo para ilustrar
Nota: tal vez la tabla no tenga sentido, pero recuerden que es para ilustrar. Es que no se me ocurre otra cosa para poner el ejemplo.
Crear tabla
Voy a crear una tabla y le pondré datos duplicados. La tabla guardará datos sobre mascotas. Para crear la tabla usamos:
CREATE TABLE mascotas (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(255) NOT NULL,
edad SMALLINT NOT NULL,
raza VARCHAR(255) NOT NULL,
genero CHAR NOT NULL
);
Llenar tabla
Para ponerle algunos datos usamos:
INSERT INTO mascotas (nombre, edad, raza, genero)
VALUES
('Maggie', 2, 'Maltés', 'F'),
('Cuco', 5, 'Chihuahua', 'M'),
('Coqueta', 3, 'Chihuahua', 'F'),
#Atención aquí abajo: El único dato que cambia es el género
('Coqueta', 3, 'Chihuahua', 'M'),
('Chucha', 1, 'Pastor alemán', 'F'),
('Maggie', 2, 'Maltés', 'F'),
('Cuco', 5, 'Chihuahua', 'M'),
('Cuco', 5, 'Chihuahua', 'M'),
('Coqueta', 3, 'Chihuahua', 'F'),
('Chucha', 1, 'Pastor alemán', 'F');
Mostrando datos
Ahora mostramos los datos con:
SELECT * FROM mascotas;
Obtenemos:
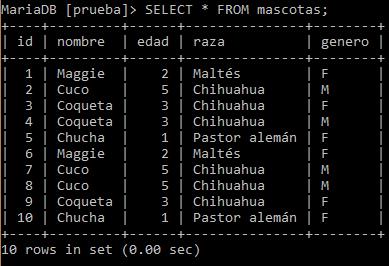
Podemos observar que se repiten los datos. Y para este ejemplo supondremos que no pueden existir dos perros que tengan el mismo nombre, la misma edad, la misma raza ni el mismo género.
Es importante notar que Coqueta se repite 3 veces (está en el #3, #4 y #9), pero en las primeras dos en realidad no se repite, ya que cambia el género.
Entonces se supone que esa fila debe quedar intacta, porque aunque los datos coincidan con la mascota #3 y #9 el género cambia.
Eliminando duplicados
Ahora ejecutaré el comando:
ALTER IGNORE TABLE mascotas ADD UNIQUE INDEX(nombre, edad, raza, genero);
Volveré a mostrar los datos:
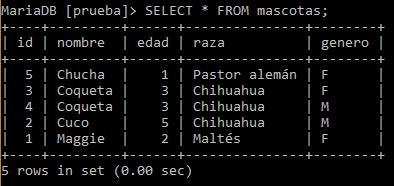
Y podemos ver que Coqueta sigue ahí, y así debe ser.
Porque indiqué que sólo quería eliminar aquellos en donde tanto el nombre, la edad, la raza y género fueran iguales. Y en éste caso cambia el género.
Si quisiéramos eliminar en donde se repitiera el nombre, la consulta sería:
ALTER IGNORE TABLE mascotas ADD UNIQUE INDEX(nombre);
Así podemos ir jugando con las columnas y los datos.
Eliminar índice
Finalmente, si no queremos que los índices estén ahí, podemos usar:
ALTER TABLE mascotas DROP INDEX nombre;
Es necesario notar que el nombre del índice es tomado de la primera columna que especificamos al indexar. Como en este caso fue nombre, entonces ese fue el nombre del índice.